[논문리뷰] RAFT: Adapting Language Model to Domain Specific RAG(2024)
1. 요약
- LLM의 Domain Adoptation을 위해 RAG 또는 Fine-tunining을 사용하는 것이 일반적임
- 그러나 RAG와 Fine-tunining을 Domain에 최적화 하기 위한 일반화된 방법이 없음
- "Open-Book" 환경에서 Domain Specific한 질문에 답하는 능력을 향상시키는 RAFT(Retrieval Aware Fine-tuning)를 제안
- RAFT는 질문과 검색된 문서가 주어졌을때 도움이 되지 않는 문서를 무시하고, 관련성 높은 문서를 잘 참고하도록 모델을 훈련
- 또한 COT(Chain of Thought)를 적용하여 모델의 추론 능력을 향상
- PubMed, HotpotQA 및 Gorilla 데이터 세트에서 평가 결과, 우수한 성능을 나타냄
2. 도입
- 법률, 의료 분야 등 전문 Domain의 영역에서 LLM을 사용하는 경우가 증가하고 있음
- 이러한 환경에서는 일반적인 지식 추론보다는 주어진 Domain 문서 지식에 기반한 답변이 중요함
- RAG는 LLM이 Domain 문서를 참조할 수 있으나, Domain에 대한 사전 학습 효과는 없음(비유: 토익 시험에 대한 사전 공부 없이 Open-Book으로 시험 응시)
- Fine-tuning은 LLM이 Domain 관련 질문에 대해 선호도 높은 답변을 생성할 수 있으나, 관련 문서 검색의 불완전성을 고려하지 못함(비유: 토익 공부를 하였으나, Closed-Book으로 시험 응시)
- 본 논문에서는 SFT(Supervised Fine-tuning)와 RAG를 결합한 RAFT를 제안
- RAFT는 Fine-tuning을 통해 Domain 지식을 사전 학습하며, 부정확한 참조 문서 검색에도 견고성을 보장함
- RAFT는 Domain에 대해 사전에 공부한 후 Open-Book 시험을 보는 것과 같음

3. 제안
3.1. Supervised Fine-tuning
- 기존의 SFT(Supervised Fine-tuning)방식은 질문과 답변 쌍으로만 구성된 Domain 데이터셋으로 LLM을 학습
- 이러한 방법은 질문에 대한 답변 능력은 향상시키지만, 검색된 문서에 대한 활용능력(Open-book 시험 능력)은 향상시키지 못함
- RAFT에서는 SFT시 질문, 검색된 문서집합, 답변으로 구성된 데이터셋을 사용하여 검색된 문서의 활용능력을 향상
- 각 데이터 포인트의 검색된 문서 집합은 답변과 관련된 문서(oracle document)와 답변과 관련 없는 문서(distractor document)로 구성
- 그리고 전체 데이터셋의 일정 비율은 oracle document가 없고 distractor document만 있는 문서집합을 사용
- distractor document만을 활용하여 올바른 답변을 출력하도록 하는 훈련은 질문에 대한 정답을 암기하는 능력(Closed-Book 시험 능력)을 향상 시키는 효과가 있음

3.2. Chain of Thought
- Chain of Thought 형태의 답변을 유도하여 정확한 답변 생성을 위한 추론 능력을 향상시킴
- 이를 위해 모든 학습데이터 생성시 GPT-4를 사용하여 Chain of Thought 형태의 답변 샘플을 생성한 후 Fine-tuning에 활용

4. 평가
4.1. Dataset
- General Domain Dataset*과 Specific Domain Dataset**에 대해 테스트 실시
*General Domain Dataset(위키피디아 기반 Open-domain 질의 응답 데이터) : Natural Questions (NQ),Trivia QA, HotpotQA
**Specific Domain Dataset(API 문서, 의료 분야 데이터) : HuggingFace, Torch Hub, and TensorFlow Hub, PubMed QA
4.2 비교 대상 Model List
- LlaMA2-7B without RAG
- LlaMA2-7B with RAG
- LlaMA2-7B with Fine-tuning(DSF)
- LlaMA2-7B with RAG & Fine-tuning(DSF + RAG)
- LlaMA2-7B with RAFT
4.3 실험 결과
- 모든 데이터셋에서 비교 대상 Model 대비 크게 나았으며, GPT-3.5 with RAG와 비교하여도 우수함
- 전반적으로 Domain Data에 대해 Fine-tuning한 모델들이 성능이 좋았음
- 그러나 기존의 Domain Fine-tuning 방식은 Context 처리와 유용한 정보 추출에 대한 학습에 한계가 있음
- RAFT는 답변 능력 및 Context 활용 능력도 함께 향상 시키므로 기존 Fine-tuning 방식보다 뛰어난 성능을 발휘함

- COT 적용한것이 안한것 대비 더 나은 성능을 보임

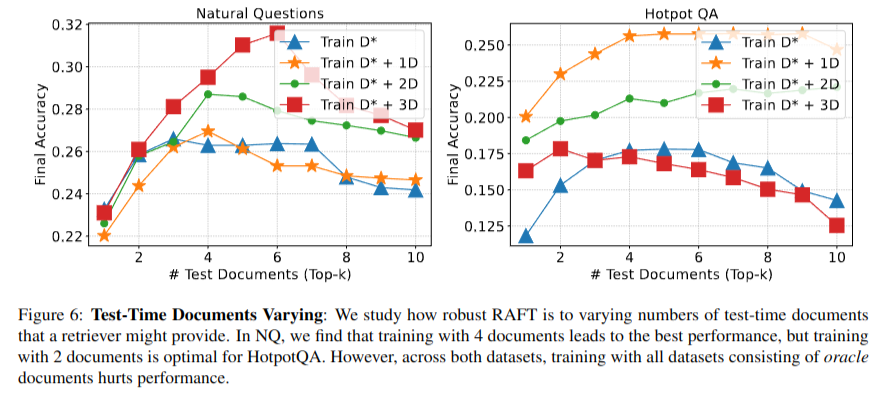
- Fine-tuning시 검색된 문서 집합을 oracle document만 구성하는 것보다 distractor document를 섞어서 구성하여 학습시키는 것이 전반적으로 성능이 더 좋으며, 다양한 Top-k 문서에서도 일관된 성능을 보임
- 이는 Fine-tuning시 답변과 관련 없는 정보를 식별하는 능력을 향상시키기 때문
5. 결론
- RAFT는 "오픈북" 설정에서 특정 도메인 내의 질문에 답하는 모델의 성능을 향상시키기 위한 훈련 전략
- Distractor document를 함께 모델을 학습시키고, COT를 적용함
- RAFT는 효과적으로 Fine-tuning된 작은 모델이 일반적인 LLM 모델보다 Domain 질문 답변 Task를 잘 수행할 수 있음을 보여줌
# 참고한 자료
https://arxiv.org/abs/2403.10131
https://github.com/ShishirPatil/gorilla