-
[논문리뷰] Efficient Estimation of Word Representations in Vector Space(word2vec, 2013)카테고리 없음 2023. 10. 8. 00:33
#요약
대규모 데이터 세트에서 단어의 벡터를 계산하기 위한 두 가지 아키텍처를 제안. 제안한 방법은 단어의 의미론적 유사성 측정 테스트에서 기존 방법 대비 낮은 계산 비용으로도 성능이 크게 향상.
#도입
현재 자연어 처리 시스템은 단어 간의 유사도라는 개념이 없었음. 최근 머신러닝 기술이 발전하면서 훨씬 더 큰 데이터 세트에서 더 복잡한 모델을 훈련할 수 있게 되었으며, 단어를 벡터로 표현하는 것은 기존 N-그램 등의 단순한 모델보다 성능이 훨씬 뛰어남. 최근 신경망으로 단어를 벡터화 하는 아케텍처가 연구 되었으나, 훈련시 많은 계산 비용이 드는 문제가 있음.
# 제안
Feedforward Neural Net Language Model (NNLM), Recurrent Neural Net Language Model (RNNLM)의 기존 모델은 학습 복잡도가 높은 단점이 있음. 대부분의 복잡도는 모델의 히든레이어에서 발생함. 본 연구에서는 히든레이어가 없는 간단한 모델을 제안함.
1. Continuous Bag-of-Words Model(CBOW)
첫 번째 제안된 아키텍처는 피드포워드 NNLM과 유사하나 히든 레이어를 사용하지 않아 학습 복잡도가 낮음. 이 모델은 일반 Bag of Word 모델과 달리 문맥에 대한 분산 표현을 사용. 투사 레이어 사이의 가중치 행렬은 모든 단어 위치에 대해 동일한 방식으로 공유.*분산 표현(Distributed representation)
원핫 인코딩과 같은 희소 표현은(sparse representation) 단어 벡터간 유의미한 유사성을 표현이 불가함. 대안으로 단어의 의미를 다차원 공간에 벡터화하는 방법을 사용하는데 이러한 표현이 분산 표현(distributed representation).
- 희소 표현 : [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0]
- 분산 표현 : [ 0.2 0.3 0.5 0.7 0.2 ... 중략 ... 0.2]
[출처] https://wikidocs.net/22660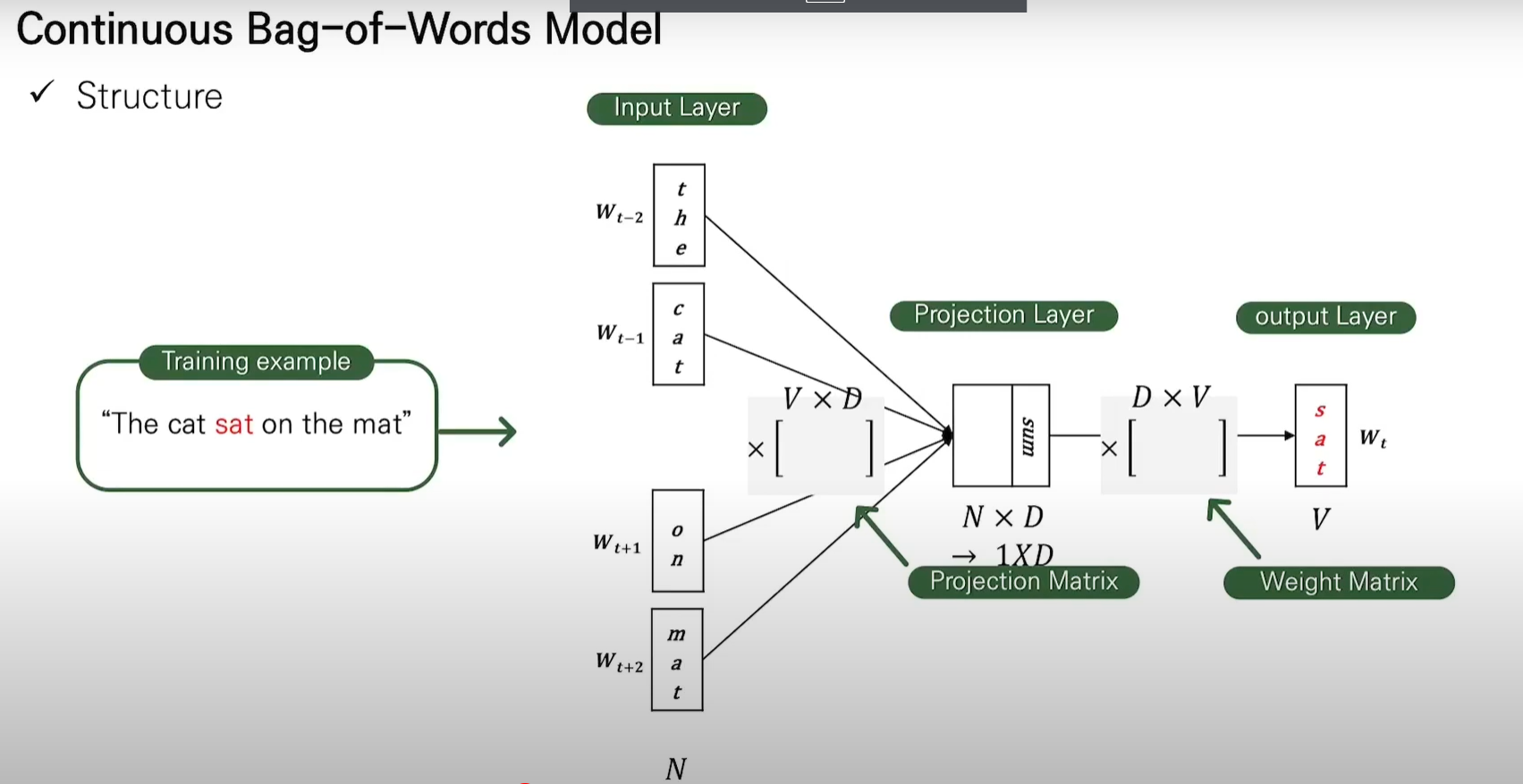
출처: https://www.youtube.com/watch?v=sidPSG-EVDo
2. Continuous Skip-gram Model(Skip-gram)
두 번째 아키텍처는 CBOW와 유사하지만, 문맥을 기반으로 현재 단어를 예측하는 대신, 현재 단어 앞뒤의 특정 범위 내의 단어를 예측.
출처: https://www.youtube.com/watch?v=sidPSG-EVDo 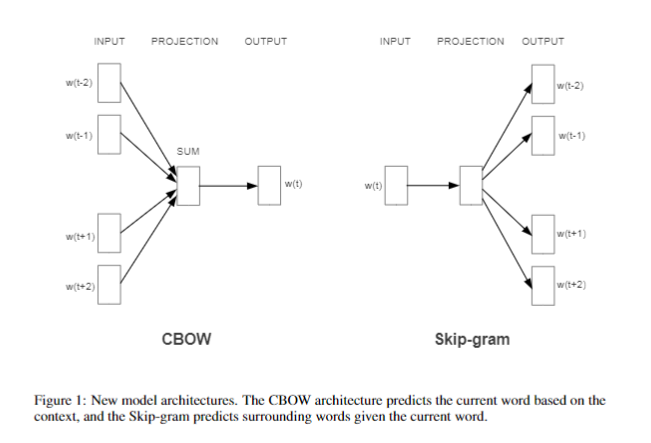
#평가
단어 벡터의 품질을 측정하기 위해 5가지 유형의 의미론적 질문과 9가지 유형의 구문론적 질문이 포함된 포괄적인 테스트 세트를 생성. 단어 벡터 학습을 위해 구글 뉴스 코퍼스 사용. 코퍼스 크기는 6B이며 단어수는 100만개로 제한.
NNLM, RNN 대비 학습 복잡도도 낮으며, 성능도 좋음.
#결론
본 논문에서는 기존 신경망 모델에 비해 매우 간단한 모델 하면서 고품질의 단어 벡터를 훈련 시킬 수 있는 아키텍처 제안함. 이 아키텍처는 계산 복잡성이 훨씬 낮기 때문에, 훨씬 큰 데이터 세트에서 매우 정확한 고차원 단어 벡터를 계산하는 것이 가능.