-
[논문리뷰] Deep Contextualized Word Representations (ELMo, 2018)카테고리 없음 2023. 10. 14. 16:57
#요약
새로운 유형의 심층 문맥화 단어 표현 제안. 심층 양방향 언어 모델 (biLM)에 대규모 코퍼스를 훈련하여 다의어도 표현 가능.
#도입
기존의 word2vec 등 사전 훈련된 단어 표현은 많은 신경 언어 이해 모델의 핵심 구성 요소이나 고품질 표현을 구현하는데는 제한이 있음. 그것들은 (1) 단어 사용의 복잡한 특성(예: 구문 및 의미론)과 (2) 이러한 사용이 언어적 맥락에 따라 어떻게 달라지는지(즉, 다의어를 모델링하기 위해)에 대해 반영하지 못하고 있음. 본 논문에서는 두 가지 문제를 직접적으로 해결하고, 기존 모델에 쉽게 통합할 수 있는 새로운 유형의 심층 맥락화된 단어 표현을 소개함.
본 논문의 단어 표현은 각 토큰에 전체 입력 문장의 함수인 표현이 할당된다는 점에서 전통적인 단어 유형 임베딩과 다름. 큰 텍스트 코퍼스에서 결합 언어 모델(LM) 목표로 훈련된 양방향 LSTM에서 파생된 벡터를 사용(ELMo). 문맥화된 단어 벡터를 학습하기 위한 이전의 접근 방식(Peters et al., 2017; McCannet et al., 2017)과 달리, ELMo 표현은 biLM의 모든 내부 계층의 함수라는 점에서 심층적임. 각 종료 작업에 대해 각 입력 단어 위에 쌓인 벡터의 선형 조합을 학습하며, 이는 최상위 LSTM 계층을 사용하는 것보다 성능을 현저하게 향상시킴.
#제안
ELMo: Embeddings from LanguageModels
대부분 널리 사용되는 word embedding과는 달리, ELMo에서 단어 표현은 고정된 벡터가 아닌 pre-trained 모델 자체를 하나의 함수 개념으로 사용.
Bidirectional language models
시퀀스 토큰들인 t1, t2....tN이 있다고 할때 순방향 LSTM은 t1, t2, tk-1 토큰의 확률을 모델링하여 tk(여기서는 context-independent token)를 예측함.
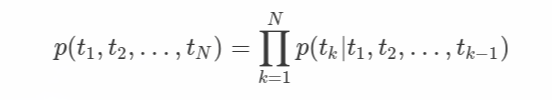
j번째 LSTM layer에서 k번째 token에 대한 forward LSTM output은 →h(k,j)임. 마지막 LSTM layer의 output인 →h(k,L)을 softmax에 넣어 최종적으로 tk+1을 예측. backward LSTM은 이와 반대로 작용.
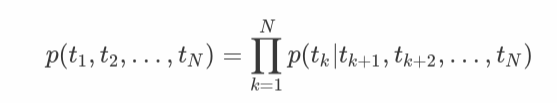
biLM은 위의 forward LSTM과 backward LSTM을 결합한 것. 두 방향에 대한 log likelihood를 최대화하는 것을 목표로 함.
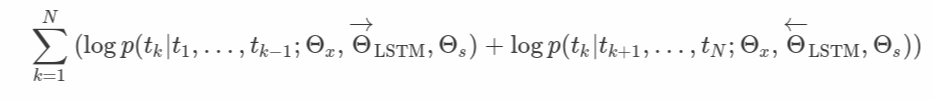
토큰 표현(Θx)의 파라미터와 소프트맥스 레이어(Θs)의 파라미터를 정방향과 역방향으로 모두 묶고 각 방향의 LSTM에 대한 파라미터는 별도로 유지.
엘모(ELMo)는 biLM에서 중간 레이어 표현들의 특정한 조합 방법임. 각각의 토큰 tk에 대하여, L-계층 biLM은 2L + 1 (순방향 LSTM + 역방향 LSTM layer +입력 표현 layer) 표현들의 세트를 계산함.
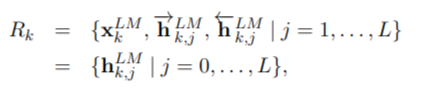
각 LSTM layer의 output hkj에 softmax-normalized weights sj를 곱한 뒤 더함. 그리고 마지막에 최종적으로 r를 곱함. sj와 r는 모두 학습되는 파라미터임.
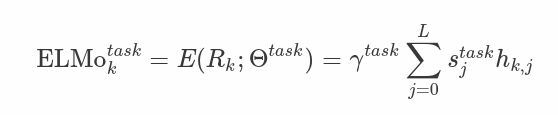
Using biLMs for supervised NLP tasks
supervised downstream task에 ELMo를 적용하는 방법은 간단. 먼저 BiLM (심층 양방향 언어 모델) 의 가중치를 고정. ElMo 벡터를 입력 벡터 (xk) 와 결합하여 task RNN (순환 신경망) 으로 전달. 원래 입력과 eLMo 벡터를 모두 포함하는 이 향상된 표현은 작업 RNN의 입력으로 사용.
Pre-trained bidirectional language modelarchitecture
ELMo는 기존 연구에서 사용한 아키텍처와 유사하지만, 양방향 공동 훈련을 지원하고 LSTM layer간 residual connection을 사용한 점이 다름. 최종 모델은 4096개의 단위와 512개의 projection이 있는 L = 2 BiLSTM 레이어와 첫 번째 레이어부터 두 번째 레이어까지의 residual connection으로 구성. 기존 단어 임베딩 방법이 고정된 어휘로 토큰을 한개의 레이어로 표현하는 것과 달리 ELMo는 각 입력 토큰에 대해 3개 layer로 표현.
#평가
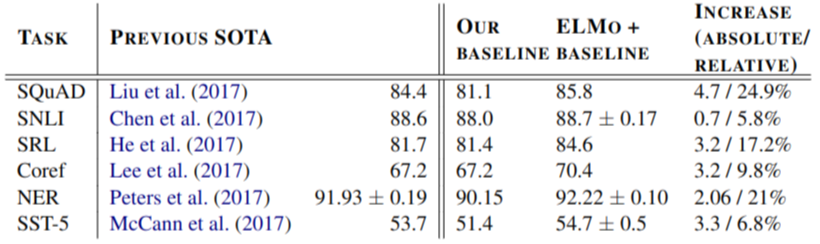
기존 모델에 eLMO를 추가하는 것만으로도 강력한 기본 모델에 비해 6~ 20% 의 성능 향상이 있었음.
#결론
biLM으로부터 고품질의 심층 컨텍스트 표현을 학습하기 위한 일반적인 접근 방식을 제안. biLM 계층이 문맥에 따라 단어에 대한 다양한 유형의 구문 및 의미 정보를 효율적으로 인코딩하며, 하나의 layer를 사용하는 것보다 모든 layer를 사용하면 모든 작업 성능이 향상된다는 사실을 확인.
#참고한 Source 출처
09-09 엘모(Embeddings from Language Model, ELMo)
 논문 링크 : https://aclweb.org/antholog…
wikidocs.net
https://cpm0722.github.io/paper-review/deep-contextualized-word-representations
[NLP 논문 리뷰] Deep Contextualized Word Representations (ELMo)
Paper Info
cpm0722.github.io