-
[논문리뷰] Improving Language Understandingby Generative Pre-Training(GPT, 2018)카테고리 없음 2023. 11. 16. 22:37
# 요약
NLP에는 다양한 Task가 존재함. Task를 수행하기 위한 레이블이 지정된 데이터가 부족하여 훈련된 모델이 잘 수행되기가 어려움. 본 논문에서는 unlabled data로 language model을 generative pre-training으로 학습한 후 Task에 대한 미세조정을 통해 성능을 높이는 방안을 제시. NLP Task 12개 중 9개에 대해 높은 성능을 입증함.
# 인트로
대부분의 딥러닝은 상당한 양의 많은 양의 수동 레이블이 지정된 데이터가 필요하므로 많은 도메인에서 적용이 제한됨. 따라서 라벨링되지 않은 데이터의 언어적 정보를 활용할 수 있는 모델이 필요함.
그러나 레이블이 지정되지 않은 텍스트에서 모델을 학습하는 것이 어려운 두 가지 이유 있음. 첫째, 어떤 최적화 목표가 전이학습에 유용한 텍스트 표현을 학습하는 데 가장 효과적인지 불분명함. 둘째, 학습된 표현을 목표 작업으로 옮기는 가장 효과적인 방법이 명확하지 않음.
본 논문에서는 Unsupervised pretraining과 Supervised fine-tuning을 조합하는 Semi-supervised 접근방식에 대해 제안.
먼저, 라벨링되지 않은 데이터에 Language modeling objective를 사용하여 신경망 모델의 초기 파라미터를 학습함(Pre-training). 그런 다음 Task에 적용하기 위해 Supervised objective를 사용하여 파라미터를 조정함(Fine-tunining).
Transfomer를 활용하여 위 방법론을 적용하였으며 NLP 12개 Task 중 9개 Task에서 SOTA를 경신함. Pre-trained model의 Zero-shot 동작을 분석하여 Downstream Task에 유용한 언어 지식을 습득한다는 것을 입증함.
# 제안
Training 절차는 두단계로 구성됨.
1) Unsupervised pre-training: 대규모 텍스트를 통해 대용량 언어모델을 학습
2) Supervised fine-tunining: 레이블이 지정된 데이터로 모델을 Target task에 맞게 조정
1) Unsupervised pre-training
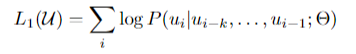
Loss function of unsupervised pre-training Loss function: i번째 토큰 u_i를 예측하기 위해 i번째 이전 k개의 토큰을 기반으로 조건부 확률 로그를 계산함.
모델은 Muulti-layer Transformer decoder를 사용. input token에 대해 Multi-head self attention 적용 후 위치별 feed-forward layer를 적용하여 target token을 생성

U=(u_k,...u-1) 컨텍스트 벡터, n=layer 수, W_e=임베딩 행렬, W_p=위치 임베딩 행렬 2) Supervised fine-tunining
Unsupervised pre-training 후 파라미터를 supervised target task에 맞게 조정하는 작업. pre-training에서 얻은 transformer 최종 출력인 h를 Wy 매개변수의 Linear layer에 통과하여 y를 예측.
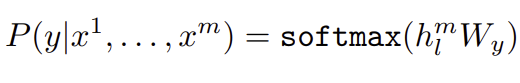

Loss funcion of supervised fine-tunining 
L_2(fine-tunining objective)와 L_1(pre-training objective)을 포함하여 Loss function L_3를 계산 Fine-tuning시 language modeling을 보조 objective(L_1)로 포함하면 supervised model의 일반화를 개선하는데 도움이 됨.
3) Task-specific input transformations
Text Classification 모델을 직접 Fine-tunining 할 수 있지만, Question Answering, Textual entailment 등의 특정 task에는 정렬된 문장 쌍 또는 문서, 질문, 답변의 삼중 항과 같은 구조화된 입력으로 구성되어 있어 수정이 필요함. 본 논문에서는 구조화된 입력을 사전 학습된 모델이 처리할 수 있는 정렬된 시퀀스로 변환하는 traversal-style approach을 사용

Traversal-style approach - Textual entailment: 전제 p와 가설 h 토큰 시퀀스를 연결하고 그 사이에 구분 기호 토큰($)를 추가.
- Similarity: 비교 대상인 두 문장의 고유한 순서가 없음. 이를 반영하기 위해 입력 시퀀스를 두 가지 가능한 문장 순서를 모두 포함하도록 수정하고 각각을 독립적으로 처리하여 Linear layer에 공급되기 전에 요소별로 추가된 두 개의 시퀀스 표현 h_m_l을 생성
- Question Answering and Commonsense Reasoning: 컨텍스트 문서 z, 질문 q, 가능한 답변 집합 {ak}이 주어짐. 문서 컨텍스트와 질문을 각각의 가능한 답변과 연결하고, 그 사이에 구분 기호 토큰을 추가하여 [z; q; $; ak]를 얻음. 이러한 각 시퀀스는 모델에서 독립적으로 처리된 다음 소프트맥스 레이어를 통해 정규화되어 가능한 답변에 대한 출력 분포를 생성.# 결과
Unsupervised pre-training
판타지, 로맨스 등 다양한 장르의 책 7000권으로 구성된 BooksCorpus dataset 사용하여 학습.
Model specifications:Transformers의 Decoder x 12개, 100 epochs, batch size = 64, BPE(Byte Pair Encoding)
Fine-tuning detail: unsupervised pre-training에서 사용했던 파라미터 재사용, Dropout 0.1, batchsize는 32
Supervised fine-tuning
classification 등 다양한 task에 fine-tuning한 결과 12개 Task 중 9개에서 SOTA 달성
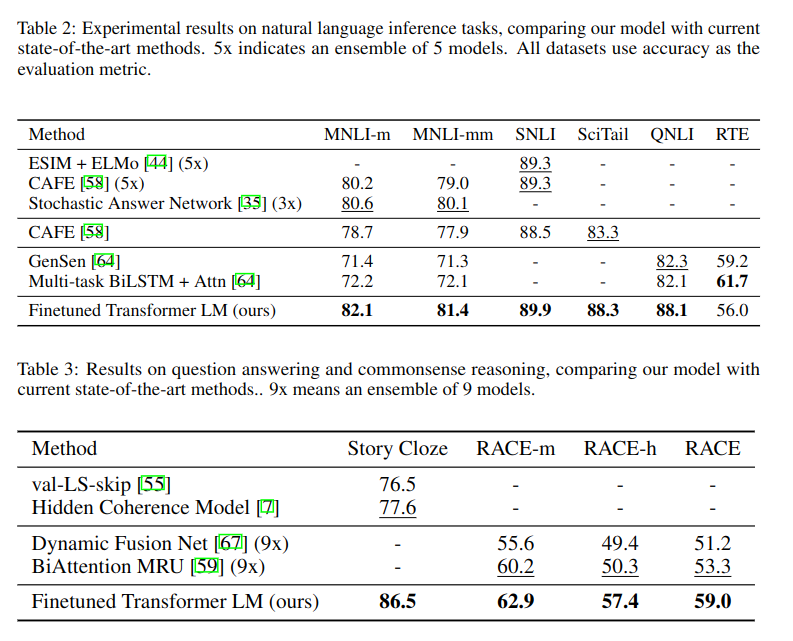

# 결론
본 논문에서는 Transformer 기바능로 Generative pre-training과 discriminative fine-tuning을 통해 다양한 NLP Task의 성능을 높일 수 있음을 입증함.
# 참고한 자료