-
[논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2019)카테고리 없음 2023. 11. 24. 22:29
# 요약
Bidirectional Encoder Representations from Transformers의 약자인 BERT라는 새로운 Language representation model을 제안.BERT는 Unlabeld text로 부터 deep bidirectional representations을 pre-training하도록 설계됨. 그 결과, Pre-trained BERT 모델은 단 하나의 추가 output layer만으로 fine-tuninig이 가능하여, Task별 아키텍처를 크게 수정하지 않고도 질문 답변 및 언어 추론과 같은 광범위한 NLP Task에서 SOTA 모델을 생성할 수 있음.총 11개의 NLP Task에서 SOTA 달성.
# 인트로
기존에는 Pre-trainined 모델 학습시 단방향으로 학습하여 Downstream task에 Fine-tunining시 성능이 제한되었음을 지적함. 본 논문에서는 Masked language model(MLM) 기반 bidirectional pre-training을 적용하여 fine-tunining의 성능을 샹항시킴. MLM은 입력에서 일부 토큰을 무작위로 Masking하고, 그 문맥만을 기반으로 Mask된 단어를 예측하는 것이 목표. 왼쪽과 오른쪽 문맥을 융합하여 Deep bidirectional Transformer 를 사전 학습함. MLM외에도 텍스트 쌍 표현을 공동으로 사전 학습하는 '다음 문장 예측' 방법도 적용.
# 모델
Bert의 학습 단계는 Pre-training과 Fine-tuning으로 나뉨.
1) Pre-training : Unlabeled data를 학습
2) Fine-tunining: Pre-training으로 학습된 파라미터로 BERT 모델을 초기화한 후 Downstream task의 labled data를 학습하여 모든 파라미터를 fine-tunining
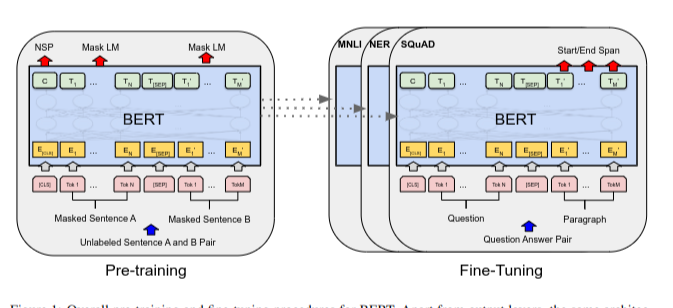
그림1. Pre-training and Fine-tunining ## Model Architecture
- BERT 아키텍처 : Multi-layer bidirectional Transformer en-coder
- BERT base model : L=12, H=768, A=12, Total parameters =110M (OpenAI GPT와 모델 사이즈 같음)
- BERT large model : L=24, H=1024, A=16, Total parameters = 340M
(L = 레이어 수, H= hidden size, A = self-attention head 수)
## Input Representations
- 30,000개의 토큰 어휘가 포함된 WordPiece 임베딩(Wu et al.,2016)을 사용
- 모든 시퀀스의 첫 번째는 [CLS] 토큰으로 시작- 문장 쌍은 하나의 시퀀스로 함께 묶음
- 두개의 묶인 문장은 특수 토큰 [SEP]으로 구분하며 모든 토큰에 학습된 임베딩을 추가하여 문장 A에 속하는지 또는 문장 B에 속하는지를 표현.
- 입력 임베딩은 E, [CLS] 토큰의 최종 hidden vector는 C, i번째 입력 토큰의 hidden vector를 Ti로 표시(그림1 참조)
- Input representation은 Token, Segment, Position Emgedding들을 합산하여 구성
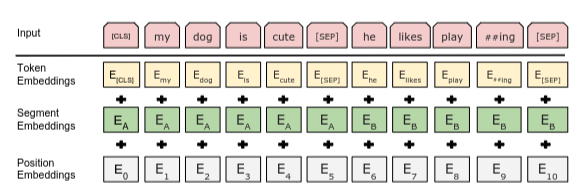
그림2. BERT input representation ## Pre-training
- 학습 방법 : Masked LM(MLM)과 Next Sentence Prediction(NSP) 두가지 적용
1) Masked LM
- input token의 15%를 masking하고 masked token을 예측하는 방식으로 deep bidirectional representation을 학습
- masking 대상 token i를 [MASK]토큰 80%, 무작위 토큰 10%, 원래토큰 10%로 대체하여 학습
2) Next Sentence Prediction
- 문장간 관계를 이해시키기 위해 다음 문장을 예측하는 방법을 학습
- 50%는 실제 다음 문장(IsNext label), 50%는 생성된 문장(NotNext lable)을 다음 문장으로 대체후 다음 문장을 예측
3) Pre-training data
- 800M 단어의 BooksCorpus와 2,500M 단어로 구성된 영문 위키피디아 데이터를 Pre-training에 사용
## Fine-tunining
- 입력 : 질의-응답, 가설-전제와 같은 downstream task의 입력 텍스트 쌍은 사전학습의 입력 텍스트 쌍과 유사
- 출력 : 감정 분류 등과 같은 Downstream task를 위해 각 Token의 representation은 output layer로 연결
# 결과
GLUE, SQuAD, SWAG 데이터셋의 다양한 NLP Task에서 SOTA 달성
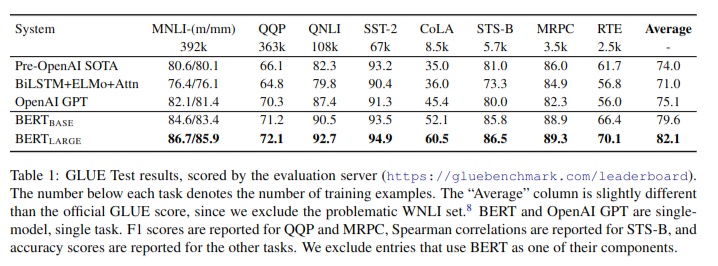
GLUE Test Result # 분석
## Pre-training
- Pre-training Task의 효과 분석을 위해 BERT base model, No NSP model, No NSP + LTR(No MLM) model의 성능을 비교
* No NSP = BERT without Next Sentence Prediction training, LTR = Left to Right(No bidirectional, No MLM)
- 평가결과 BERT base > No Nsp > LTR & No NSP 순으로 성능이 좋음. Bidirectional Architecture가 성능에 중요한 영향
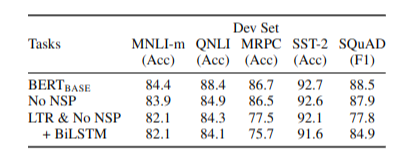
## Model Size
- Model Size가 클수록 성능도 향상
## Feature-based Approach with BERT
- Pre-trained BERT model을 특정 Task에 적용하는 방법 중 Fine-tuning(Pre-trained model에 간단한 분류 layer를 추가하고 모든 파라미터를 fine-tuning하는 방법) 대신 Feature-based approach를 적용해봄.
- Feature-based approach에서도 양호한 성능을 나타냄
- BERT가 Fine-tuning and feature-based approach에 모두 효과적임
# 결론
- Deep bidirectional architectures를 통해 Pre-training된 모델이 광범위한 NLP Task를 성공적으로 수행함을 입증
# 참고한 자료
https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org