-
[논문리뷰] Language Models are Unsupervised Multitask Learners(2019, GPT-2)카테고리 없음 2023. 12. 30. 23:08
# 요약
- 질문 답변, 기계 번역, 요약 등의 NLP Task들은 일반적으로 Task Specific Data에 대한 지도학습을 적용함
- Task Specific Training 없이 대량의 Web Text를 통해 Model을 학습하는 방법을 제안
- Zero-shot만으로 다양한 Task에서 우수한 성능을 기록
- Language Model의 용량이 Zero-shot 성능에 유관함을 입증
# 인트로
- 기존 NLP Model 들은 대량의 Task Specific Data를 학습하는 방식으로 개발됨
- 이러한 방식은 데이터의 변화에 민감하며, 특정 Task에만 잘 작동 되는 제약이 있음
- 본 논문에서는 Data labeling이 필요없고, 많은 Task를 수행할 수 있는 일반화된 모델 개발을 추구
# 제안
- 최근 Transformer 등의 연구로 Language Modeling의 Representation이 크게 향상됨
- 단일 Task에서 Language Model은 p(output | input)의 조건부 확률을 추정하는 것임
- 다양한 Task에 적용가능한 범용 Language Model은 p(output | input, task)를 잘 모델링 할수 있어야 함
- 충분한 Capa의 Language Model이 자연어의 시퀀스와 추론 방법을 학습하면 다양한 Task에서 좋은 성능을 보일 것임
- 이러한 방법은 Language Model이 Unsupervised multitask learning을 수행하는 것이며 다양한 Task에 대해 Zero-shot test를 수행하여 성능을 검증함
## Training Dataset
- Web crawl을 통해 특정 Domain에 치우치지 않는 대규모 텍스트 데이터셋인 'WebText' 구축
- WebText는 총 8백만개 문서가 포함된 40Gb 용량의 텍스트 데이터셋
## Input Representation
- 단어수준의 LM과 byte 수준의 LM의 중간형태인 BPE 인코딩을 적용
## Model
- Transfomer Architecture 적용한 OpenAI GPT 모델을 기본으로 함
- Layer Normalization이 각 sub-block의 input으로 이동하여 residual network와 유사하게 작용
- Additional layer normalization이 마지막 self-attention block 다음에 추가 됨.
- Residual layer의 가중치 초기화 시 1/√N의 factor로 조정. N은 Residual layer의 수
- 어휘는 50,257개로 확장, Context size를 512에서 1024 token으로 증가시킴
# 결과
- Language Modeling : Zero-shot으로 8개 중 7개 Dataset에서 SOTA 달성
- LAMBADA : Text의 long-range dependencies 관련 Dataset. PPL과 ACC 에서 SOTA 달성
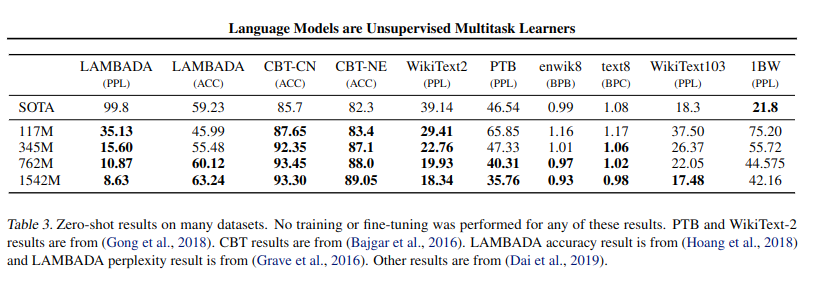
Language Modeling & LAMBADA Dataset Result - Children's Book Test : 품사에 따른 성능 비교를 위한 Dataset, 기존 SOTA를 크게 능가하였으며, Human과 유사한 성능
- Winograd Schema Challenge : 언어 의미의 중의성(ambiguities)을 해석하는 Dataset. SOTA 달성
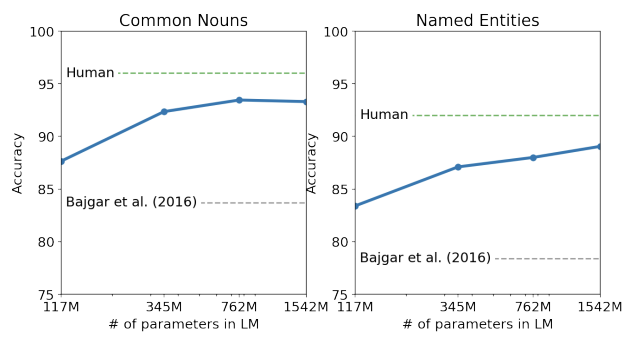

Children's Book Test & Winograd Schema Challenge Result - Question Answering : GPT-2는 4.1%의 정확도로 기존의 모델들보다 5.3배 높은 QA 정확도를 기록
## Generalization vs Memorization
- Dataset(Train data와 test data)에 중복 데이터가 있는 경우, 모델의 성능을 과대 평가할 수 있음
- Data의 중복이 많으면 Model은 Generalization이 아닌 Memorization에 치우치게 됨
- 따라서 GPT-2에 사용된 WebText dataset에서도 이러한 중복 여부와 영향을 확인 해야 함
- WebText Train dataset은 Test dataset과 평균적으로 3.2%의 중복이 있음
- 그러나 다른 Model에 사용된 데이터셋들은 WebText보다 더 많은 평균 5.9%의 중복이 있었음

- 또한 GPT-2의 모델 사이즈별 WebText의 학습 성능을 분석한 결과, train set과 test set에서 성능이 비슷하며 model size가 커질 수록 성능이 계속 올라감
- 즉 더 많이 Trainin에 투자할 경우 성능이 더 오를 수 있으며 현재 GPT-2는 WebText에 Underfitting 되었음을 시사
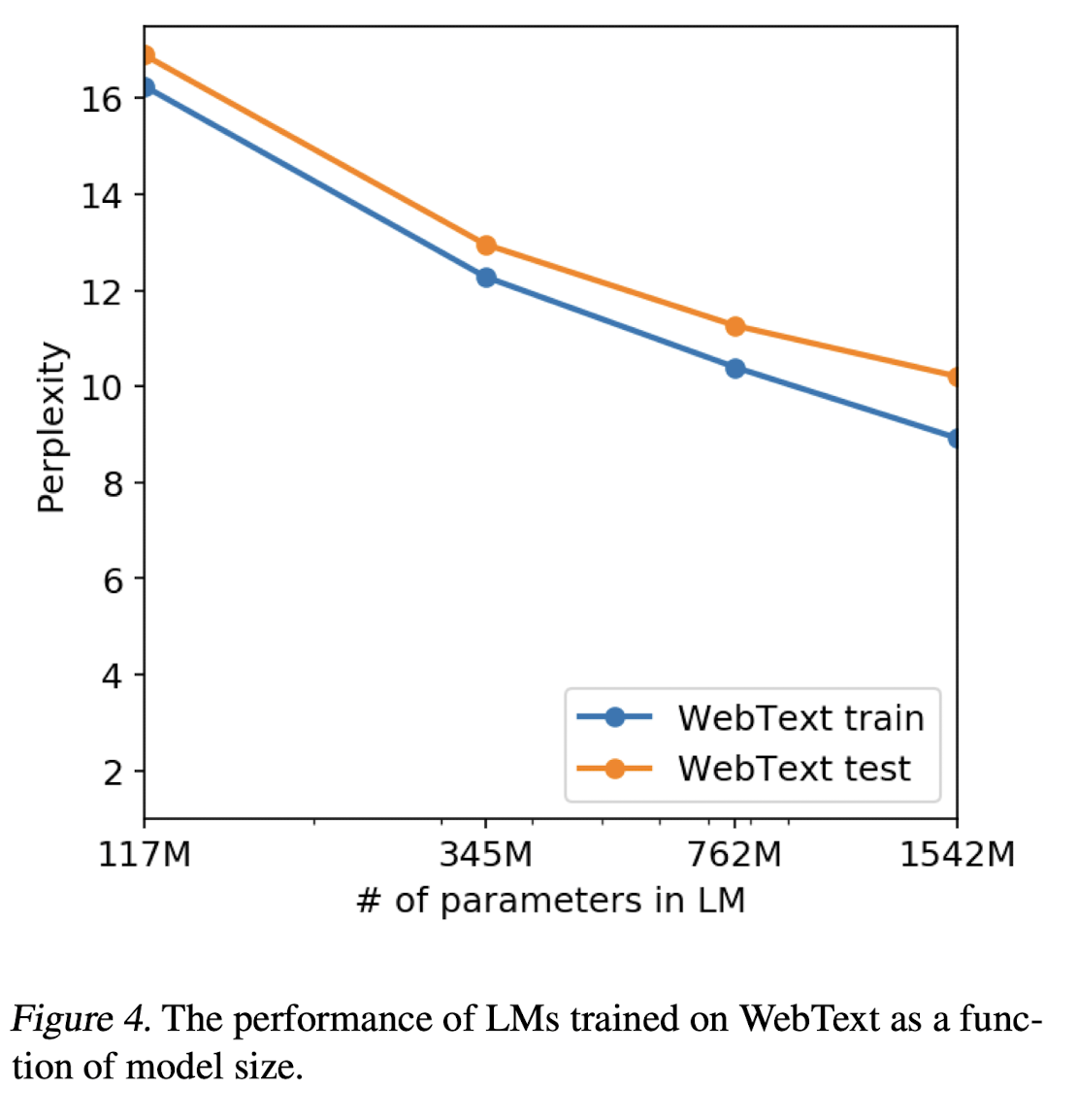
# 결론
- Large language model이 충분히 크고 다양한 dataset을 학습하면 다양한 domain과 dataset에서 잘 작동함을 입증
- GPT-2는 zero-shot에서 다양한 Dataset(8개중 7개)의 SOTA를 달성
- 충분히 다양한 Text Corpus에서 학습된 high-capacity의 LM이 Supervision 없이도 다양한 task를 잘 수행하는 하는 것을 입증
# 참고한 자료
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdfhttps://blog.naver.com/mewmew16/223159788855