-
[논문리뷰] Finetuned Language Models Are Zero-Shot Learners(2022, Instruction following)카테고리 없음 2024. 1. 12. 12:55
# 요약
- Language Model의 Zero-shot 학습 능력을 향상시키는 간단한 방법을 연구
- 명령어를 통해 설명된 Dataset에서 Instruction tuninig이 Zero-shot 성능을 크게 향상 시키는것을 입증
- 137B의 Pre-trained LM을 명령어 템플릿을 통해 변형된 60개 이상의 NLP 데이터 세트에 대해 Instruction Tuninig 수행
- FLAN(Instruction Tuned Model)을 평가한 결과, FLAN은 수정하지 않은 모델보다 성능이 크게 향상되었으며 평가한 25개 데이터 세트 중 20개에서 제로 샷 175B GPT-3를 능가
# 서론
- GPT-3(Brown et al., 2020)와 같은 대규모 언어 모델(LM)은 다양한 Task를 매우 잘 수행
- 그러나 Zero-shot 학습에서는 좋지 못하며 Few-shot 대비 성능이 많이 떨어짐
- 이유는 Few-shot의 예시가 없으면 사전 학습 데이터의 형식과 유사하지 않은 Prompt에서 모델은 잘 수행하지 못함
- 본 논문에서는 자연어 명령을 통해 NLP 작업을 설명할 수 있다는 직관을 활용한 간단한 방법으로 대규모 언어 모델의 Zero-shot 성능을 개선할 수 있음을 입증
- 60개 이상의 NLP Dataset에서 평가한 결과 Zero-shot 성능을 크게 개선함을 확인
- 또한 Instruction-tuning에서 작업 클러스터 수를 늘리면 보이지 않는 작업의 성능이 향상되며, 모델 규모가 충분할 때만 Instrution-tuning의 이점이 생긴다는 사실을 발견
- 인스트럭션 튜닝은 언어 모델이 순전히 지시를 통해 설명된 작업을 수행할 수 있는 유망한 능력을 보여줌

# FLAN: Instruction Tuning Improves Zero-Shot Learning
Unseen Task에 대한 성능을 평가하기 위해 데이터 세트를 작업 유형별로 클러스터링 하고 각 작업 클러스터를 평가할 수 있도록 유지하면서 나머지 모든 클러스터에 대한 Instruction Tuning을 수행
## Task & Templates
- 연구계에서 쓰이는 기존의 Dataset를 변환하여 새 Dataset을 구축
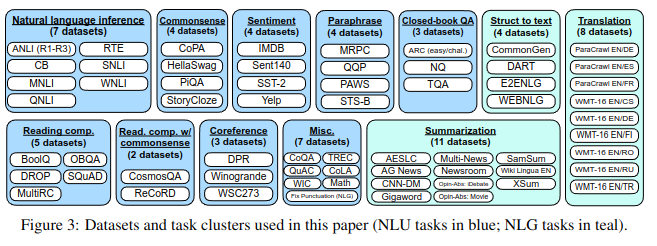
- Tensorflow 데이터 세트에서 공개적으로 사용 가능한 62개의 텍스트 데이터 세트를 수집
- 각 데이터 세트는 12개의 작업 클러스터 중 하나로 분류됨(Figure 3 참고)
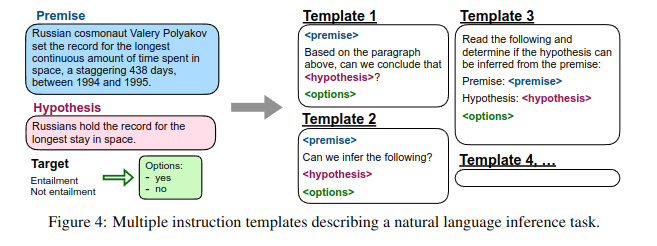
- 각 데이터 세트에 대해 Instruction을 사용해 해당 데이터 세트의 작업을 설명하는 10개의 고유 템플릿을 작성
- 템플릿 대부분은 원래의 Task를 설명하지만, 다양성을 높이기 위해 각 데이터 세트 마다 최대 3개의 'Turned the task around' 템플릿도 포함시킴(예: 감정 분류의 경우 영화 리뷰를 생성하도록 요청하는 템플릿 포함)
## Evaluation Splits
- Unseen Task에 대한 성능 평가를 위해 'Unseen Task'에 대한 정의가 필요
- A 클러스터에 속하는 Dataset으로 테스트 하기 위해 A 클러스터 외 다른 클러스터들을 Instruction Tuninng한 모델로 테스트 하는 방법을 적용
## Classificaiton with Options
- Dataset Test시 Output 형태는 분류 또는 텍스트 생성
- FLAN은 Decoder 기반 LM의 Instruction Tuning 버전 이므로 텍스트 생성 Output을 출력하는 것은 문제가 없음
- 분류의 경우, 'Yes', 'No', 'It is not possible to tell' 등의 옵션을 제시하여 해당 옵션 중 응답을 선택하도록 변환함
## Training Detail
① Model
- LaMDA-PT(Transformer Decoder 기반, 137B), BPE 토큰 적용
- 웹문서/대화 Data/Wikipedia가 포함된 32,000개의 어휘가 포함된 Data로 Pre-training 됨
② Instruction Tunining
- FLAN은 LaMDA-PT를 Instruction Tuning 버전
- 각 Dataset에서 무작위로 각 3만개의 샘플을 추출.
- AdafactorOptimizer, Learning rate 3e-5, Batch Size 8,192, Gradient Step 30k 적용
- TPUv3(128 Core)에서 60시간 소요
.
# 결과
- 자연어 추론, 독해, QA, 번역, 상식적 추론 등의 Task에 FLAN을 평가
- Dataset을 Task Cluster로 그룹화 하고 평가 대상 Cluster외 나머지 모든 Cluster에서 Instruction Tuning 하여 실시
- FLAN과 Instruction Tuning을 하지 않은 LaMDA-PT, LaMDA-PT의 Few-shot learning 비교 결과, 대부분의 Dataset에서 FLAN이 크게 나음
- FLAN과 GPT-3, GLaM의 Zero-shot과 비교 결과, 25개 Dataset 중 20개 Dataset에서 FLAN이 우수함
- 종합적으로, Instruction Tunining은 Instruction으로 자연스럽게 언어화된 작업(예: 자연어추론, QA, 번역 등)에 효과적
- 언어 모델링으로 직접 공식화된 작업(예: 불완전한 문장이나 단락을 마무리하는 형식의 상식 추론 등)에는 덜 효과적
- Downstream Task가 원래의 언어 모델링 사전 학습 목표와 동일한 경우(즉, 명령어가 대부분 중복되는 경우) Instruction Tunining이 유용하지 않음을 의미

# 분석
## Instruction Tuning Cluster의 수
- Instruction Tuning Cluster와 작업을 추가할수록(감정 분석 클러스터 제외) 성능이 향상
- 이는 새로운 작업에 대한 제로샷 성능에 대한 제안된 Instruction Tuning 접근법의 이점을 증명
## Scaling Law
- 68B이상의 큰 모델에서는 Instruction Tuning이 성능을 크게 향상 시킴
- 8B 이하에서는 Instruction Tuning이 오히려 성능을 약화 시킴
- 작은 모델의 경우, Instruction Tuning에 사용된 40개의 Task 학습 시 모델 용량에 과부하가 발생하여 새로운 Task에 성능이 저하
## Instruction Tuning의 역할
- Instruction의 Tuning 이 없는 단순한 Fine-Tuning 보다 Instruction with Fin-tuning(FLAN)이 성응이 더 좋음
- Unseen Task에 대한 Zero-shot 성능에 Instruction Tuning이 중요함
## Instruction with Few-shot examples
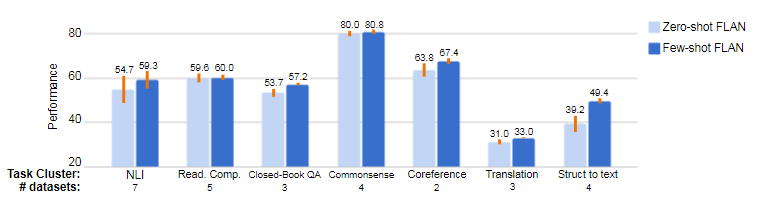
- 추론 시점에 Few-shot 적용시 Zero-shot FLAN 대비 모든 Task에서 성능이 향상 됨.
- 특히 구조체에서 텍스트로의 변환, 번역, Closed-QA와 같이 Output space가 크고 복잡한 작업에 효과적
- 이는 예제가 모델이 출력 형식을 더 잘 이해하는 데 도움이 되기 때문
## 한계점
- Cluster에 Task를 할당할때 주관성이 개입됨
- 일반적으로 한 문장으로 구성된 비교적 짧은 Instruction만을 사용
- FLAN 137B의 규모 때문에 서비스 비용이 많이 듬
# 결론
- Instruction으로 대규모 언어모델의 Task 적용 성능을 향상 시킬 수 있는 간단한 방법을 제시
- FLAN은 GPT-3 대비 다양한 Task에서 좋은 성능을 보이며, 대규모 언어 모델이 Instrution을 따를 수 있는 능력을 보여줌
# 참고한 자료
https://arxiv.org/abs/2109.01652