-
[논문리뷰] Training language models to follow instructionswith human feedback(2022, InstructGPT)카테고리 없음 2024. 1. 24. 22:08
# 요약
- Language Model의 크기를 증가시키는 것이 반드시 사람의 의도를 잘 파악하지는 않음
- LM을 다양한 Task에서 사용자의 의도에 맞게 Fine-tuning 하는 방법을 제시
- GPT-3 보다 100배 작은 매개변수를 가진 InstructGPT는 GPT-3 보다 더 사람의 의도에 맞는 출력을 생성함
# 도입
- LM은 Few-shot 프롬프팅을 통해 다양한 NLP Task 적용이 가능
- 그러나 사실을 지어내거나, 사용자 지침을 잘 따르지 않는 등 의도하지 않은 출력이 발생함
- 원인은 LM에 사용되는 목표, 다음 토큰을 예측하는 목표가 "사용자의 지시를 유용하게 따르기"라는 목표와 다르기 때문
- 본 논문에서는 사람의 피드백을 통한 강화 학습(RLHF)을 사용하여 다양한 지침을 따르도록 GPT-3를 Fine-tuning함
- 이 방법은 인간의 선호도를 보상 신호로 사용하여 모델을 Fine-tuning 함
- 그 결과 GPT-3 보다 InstructGPT의 파라미터가 100배 이상 적음에도 더 나은 출력을 생성함
- InstructGPT 모델은 TruthfulQA 벤치마크에서 GPT-3보다 2배 더 진실된 답변 생성
- "Closed Domain" Task에서, 입력에 없는 정보를 구성하는 빈도가 GPT-3의 절반 정도로 나타남
- InstructGPT는 편향성은 개선되지 않음- 전반적으로, 인간의 선호도를 사용하여 LM을 Fine-tuning하면 광범위한 작업에서 언어 모델의 성능이 개선됨을 확인
- 그러나 안전성과 신뢰성을 개선하기 위해 해야 할 일이 많이 남아 있음을 보여줌
# 적용 방법
## Dataset
- Dataset은 Prompt(지시, X값)와 Response(답변, Target)로 구성
[Prompt]
(1) Plain : 임의의 Task 제시 (작성 by 라벨러)
(2) Few-shot : 하나의 Instruction과 여러 개의 질문/응답 쌍 제시 (작성 by 라벨러)
(3) User-baed : OpenAI API의 사용사례에 해당되는 프롬프트 생성 (수집 from API)[Response]
라벨러가 상기 Prompt에 대해 답변을 작성함
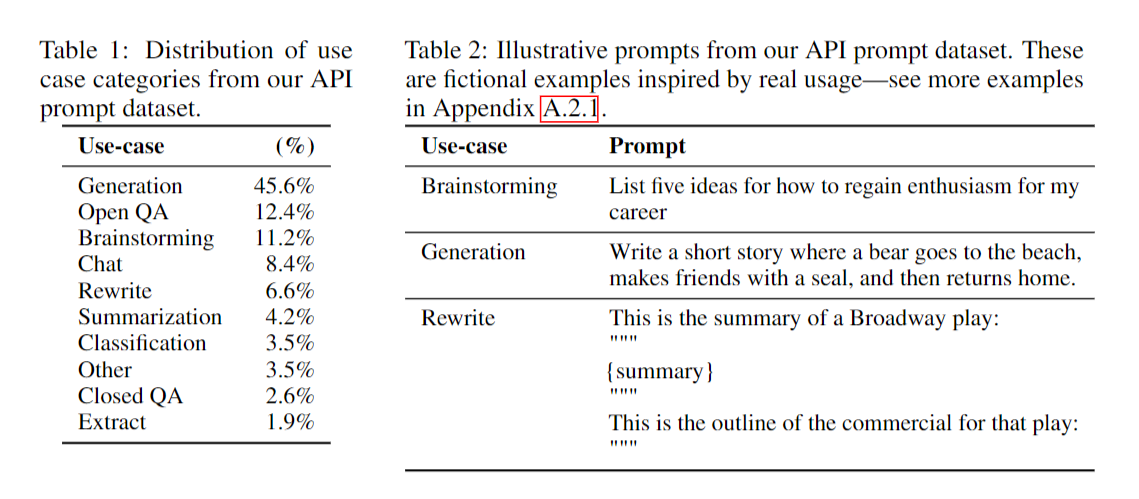
API로 수집된 Prompt 데이터셋 분포 및 예시 - 위에서 생성한 데이터셋을 샘플링하여 세가지 목적의 데이터세트를 구축
(1) SFT(Supervied Fine-tuning) 모델을 훈련하는 데 사용되는 SFT 데이터 세트 (13,000개 프롬프트)
(2) 보상 모델(RM)을 훈련하는 데 사용되는 모델 출력의 라벨러 순위가 포함된 RM 데이터 세트 (33,000개 프롬프트)
(3) RLHF 미세 조정을 위한 입력으로 사용되는 인간 라벨이 없는 PPO 데이터 세트 (31,000개 프롬프트)
## Models(Instruct GPT)
- GPT-3를 두가지 방법으로 모델을 훈련함
1) Supervised Fine-tuning(SFT)
- 지도 학습을 사용하여 GPT-3을 Fine-tuning
- Input: Prompt, Output: Response 형태로 학습
- 6 epochs, cosine learning rate decay, dropout of 0.2 적용
- 검증 세트의 보상 모델 점수를 기반으로 최종 SFT 모델을 선택
2) Reinforcement learning(RL)
2-1) Reward modeling(RM)
- 강화학습에 사용될 보상 모델(RM)을 지도학습을 통해 생성
- Input: Prompt & Response, Output: 보상 점수
- SFT 모델로 한개 Prompt 당 4~9개 Response 생성
- 라벨러들이 생성된 Response에 대해 선호도 순위를 정함
- 순위 결과를 쌍으로 조합하여 Target을 생성하고, 이를 바탕으로 보상 점수를 생성하도록 학습

출처 : https://www.youtube.com/watch?v=8vG9cIWC8TQ&list=WL&index=3 2-2) Reinforcement learning Modeling
- 앞서 생성한 보상모델(RM)을 활용한 강화학습 기반으로 SFT 모델을 Fine-tuning
- 강화학습에는 PPO 알고리즘 적용
- Input: Prompt -> Action: Response -> RM(Input: Prompt & Response) Output: 점수
- 과적화를 방지하기 위해 KL 페널티 추가
- ptx term : Pre-training gradient를 함께 사용하여 특정 Task에서 성능저하를 방지
- PPO , PPO-ptx 두가지 모델 생성
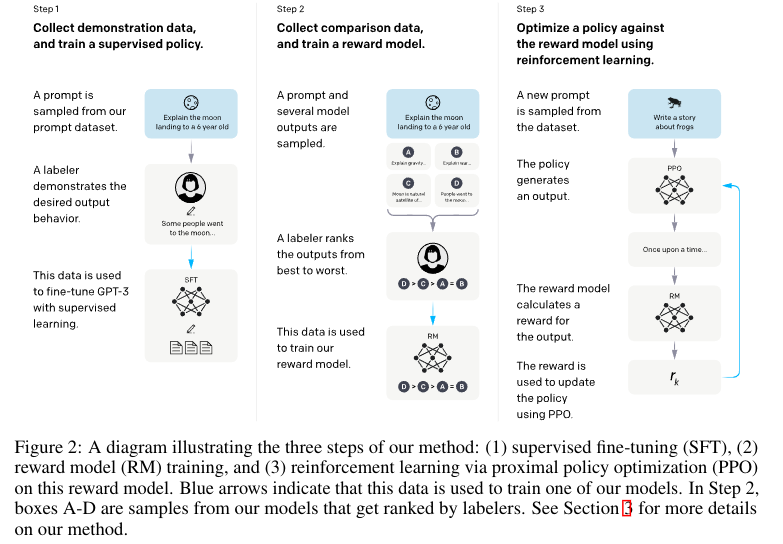
# 결과
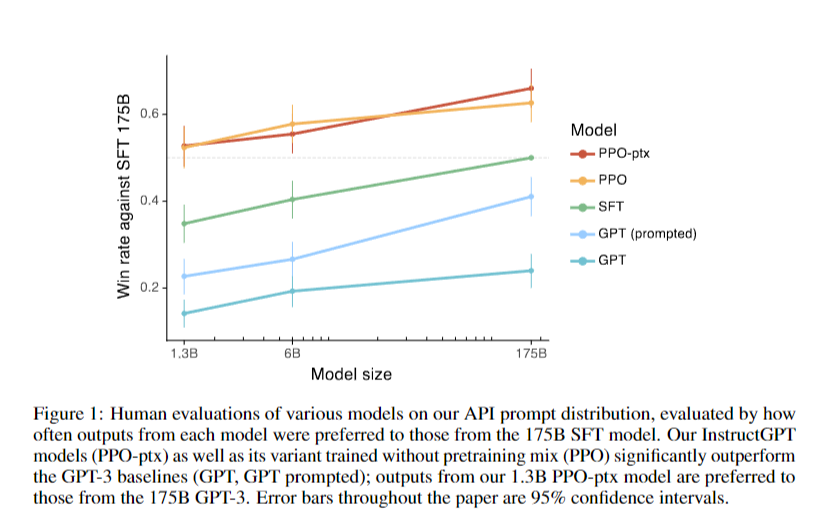
## Results on the API distribution
- 라벨 제작자들은 GPT-3의 출력보다 InstructGPT 출력을 훨씬 더 선호
- 학습 데이터를 생성하지 않은 '홀드아웃' 라벨러들도 InstructGPT 출력을 선호함

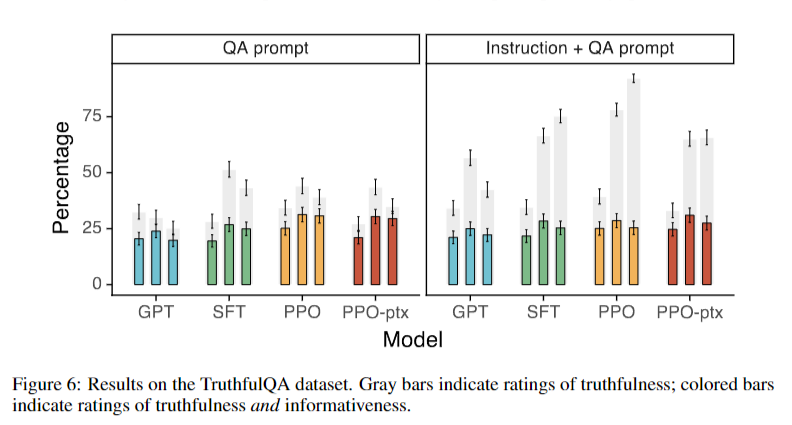
## Results on public NLP datasets
- TruthfulQA 데이터 세트 평가 결과 InstructGPT 모델은 GPT-3에 비해 진실성이 개선됨
- InstructGPT는 GPT-3에 비해 독성이 약간 개선되었지만 편향성은 개선되지 않음
## Qualitative results
- InstructGPT 모델은 RLHF Fine-tuning 분포를 벗어난 명령어에 대한 일반화 가능성을 보여줌
- 특히, 영어가 아닌 언어로 된 명령어를 따르고 코드에 대한 요약과 질의응답을 수행할 수 있는 능력을 보임
- InstructGPT는 여전히 간단한 실수를 저지름
예) 간단한 질문이 주어지면 문맥상 하나의 명확한 답이 있는데도 질문에 대한 답이 하나도 없다고 말함
예) 명령어에 여러 개의 명시적 제약 조건이 포함되어 있으면 모델의 성능이 저하
# Discussion
## Implications for alignment research
- 모델 정렬을 향상시키는 데 드는 비용은 사전 훈련에 비해 크지 않습니다.
- RLHF는 언어 모델을 사용자에게 더 유용하게 만드는 데 매우 효과적이며, 모델 크기를 100배로 늘리는 것보다 더 효과적- InstructGPT가 '지시 사항 따르기'를 일반화함을 확인
- Fine-tuning으로 인한 성능 저하를 대부분 완화할 수 있음
- 기존의 추상적 연구와 다르게 실제 사용되는 AI 시스템의 연구를 통해 정렬 기법을 검증
## Limitations
- InstructGPT 모델의 동작은 인적 피드백에 의해 결정됨. 라벨러의 정체성, 신념, 문화적 배경 등에 영향을 받을 수 있음
- 모델은 유해하거나 편향된 결과물을 생성할 수 있음. 편향을 지시받았을때, GPT-3 모델보다 더 많은 유독성 출력을 생성
## Open questions & Broader impacts
- 이 작업의 목적은 대규모 언어 모델을 인간의 의도에 맞게 조정하여 그 영향을 개선하 것
- 정렬 실패는 특히 안전이 중요한 상황에서 심각한 결과를 초래할 수 있으므로 사람의 의도와 일치하는지 확인하는 것이 중요
- 정렬 기법은 대규모 언어 모델과 관련된 안전 문제에 대한 완전한 해결책이 아니며, 위험이 높은 영역에 적용시 신중한 고려가 필요- 사용자 의도에 Align 시키는 것은 단순한 접근 방식이지만 윤리 이슈를 고려하고, 공정한 조정 원칙을 결정하기 위한 연구 필요
# 참고한 자료
https://arxiv.org/abs/2203.02155
Training language models to follow instructions with human feedback
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not ali
arxiv.org