-
[논문리뷰] LLaMA: Open and Efficient Foundation Language Models(2023)카테고리 없음 2024. 2. 1. 22:25
# 요약
7B에서 65B 매개변수를 포함하는 LM인 LLaMA를 제안. 공개적으로 사용 가능한 데이터셋만을 활용하고, 초 대규모로 모델 사이즈를 키우지 않고도 좋은 성능을 낼 수 있음을 입증함.
# 서론
- 최근의 연구는 LM의 크기와 성능이 선형적 관계라는 가정으로 LM의 크기를 키우는 방향으로 연구되고 있음
- 그러나 Hoffmann 등(2022)의 최근 연구에 따르면, 주어진 컴퓨팅 리소스 내에서 최고의 성능은 가장 큰 모델이 아니라 더 많은 데이터로 훈련된 더 작은 모델임
- 모델의 추론과 서빙을 고려할때 우리는 적정한 크기의 성능 좋은 LM이 필요함
- 본 논문에서는 더 많은 토큰을 학습시켜 최고의 성능을 달성하는 적정한 크기의 LM을 추구함
- 이렇게 생성된 LLaMa는 7B ~ 65B 파라미터로 기존의 초거대 LM인 SOTA 들과 비교하여 경쟁력 있는 성능을 보임
- LLaMa는 기존 모델과 달리 공개적으로 이용 가능한 데이터만 사용하므로 오픈 소싱과 호환됨
# Approach
## Pre-training Data
- 학습 데이터 세트는 Table 1에 나와 있는 것처럼 다양한 도메인을 포괄하는 여러 소스가 혼합. 대부분 공개 데이터

학습 데이터셋 구성 - 토크나이저는 BPE 토크나이저 적용
- 전체 학습 데이터 세트에는 토큰화 후 약 1.4T의 토큰이 포함됨
## Architecture
- 트렌스포머 아키텍처 기반 모델 구현
- Pre-normalization: 훈련 안정성을 향상시키기 출력 대신 각 트랜스포머 하위 계층의 입력을 정규화
- SwiGLU activation function: SwiGLU 활성화 함수로 ReLU 비선형성을 대체- Rotary Embeddings: 절대 위치 임베딩을 대신 Rotary positional embeddings을 네트워크의 각 계층에 추가
## Optimizer
- AdamW 옵티마이저 사용
- Cosine learning rate schedule 적용. 0.1의 가중치 감쇠와 그라디언트 클리핑 1.0을 사용## Efficient implementation
- 학습속도 개선을 위해 Causal multi-head attention을 효율적으로 구현
- Attention 가중치를 저장하지 않고 언어 모델링 작업의 인과적 특성으로 인해 마스킹되는 키/쿼리 점수를 계산하지 않음
- 체크포인팅을 통해 백워드 패스 중에 다시 계산되는 활성화의 양을 줄임
- 65B 매개변수 모델을 80GB RAM의 2048 A100 GPU에서 1.4T 토큰이 포함된 데이터 세트에 대한 학습시 약 21일 소요
# 결과
## Performance
- Zero-shot 및 Few-shot Task에 대해 총 20개의 벤치마크를 테스트
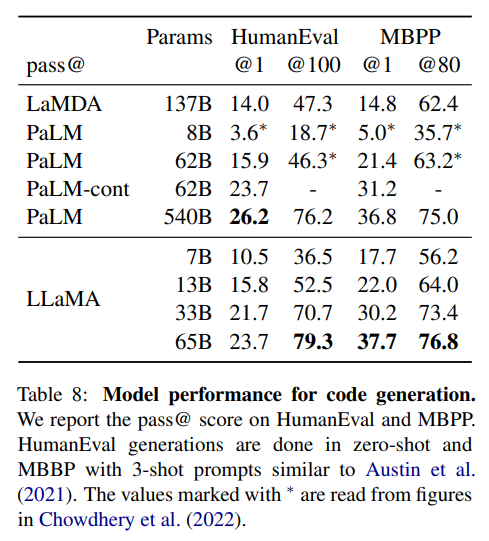
- Common Sense Reasoning, NaturalQuestions, TriviaQA, Reading Comprehension, Code Generation Task에서 동급(약 5B) 모델중 가장 성능이 좋았음
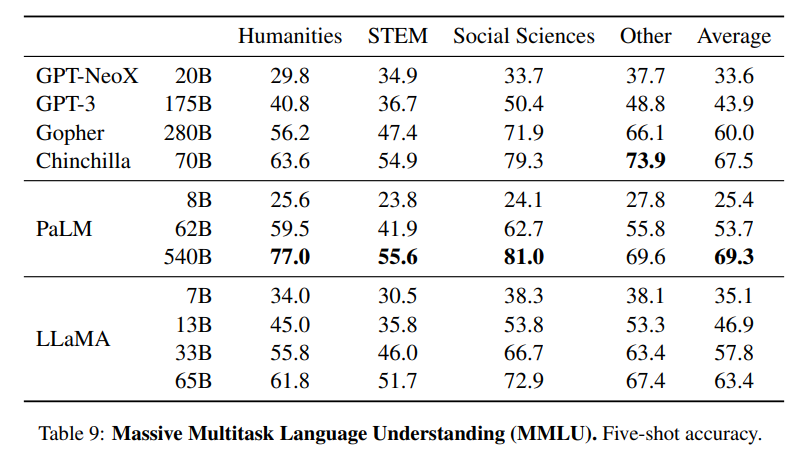
- Quantitative reasoning, Massive multitask language understanding에서는 동급 SOTA 모델 보다 약간 미흡함

## Bias, Toxicity and Misinformation
- 모델 크기가 커질 수록 Toxic Prompt를 생성할 확률이 높아짐을 확인
- 편향성은 GPT, OPT 대비 Llama가 적음
- Truthful 정도도 GPT보다 크게 나음
# 결론
- LLaMA-13B는 GPT-3보다 10배 이상 작으면서도 성능이 뛰어나며, LLaMA-65B는 Chinchilla-70B 및 PaLM-540B와도 경쟁력이 있음
- 이전 연구와 달리 공개적으로 사용 가능한 데이터로만 훈련하여 최첨단 성능을 달성할 수 있다는 것을 입증- 데이터셋의 규모를 키우면서 성능이 향상되는 것을 확인했기 때문에 향후에는 더 큰 코퍼스로 훈련된 더 큰 모델을 출시할 계획
# 참고한 자료

