-
[LlamaIndex] Advanced Retrieval Strategies카테고리 없음 2024. 2. 5. 13:04
지금까지 LlamaIndex로 RAG를 구현하는 방법들을 알아봤습니다. 이번에는 고급 RAG 구현하는 몇가지 방법을 알아보겠습니다.
○ Query Transformation
사용자 쿼리는 RAG 쿼리 엔진, 에이전트 또는 기타 파이프라인의 일부로 실행되기 전에 여러 가지 방법으로 변환 및 분해될 수 있습니다.
1. Routing: 쿼리는 유지하되, 쿼리가 적용되는 Tool을 선택합니다.
2. Query-Rewriting: 다양한 방법으로 쿼리를 다시 작성합니다.
3. Sub-Questions: 쿼리를 여러 개의 하위 질문으로 분해합니다.
4. ReAct Agent Tool Picking: 초기 쿼리가 주어지면 1) 선택할 Tool과 2) 해당 Tool에서 실행할 쿼리를 식별합니다.# Routing
이 예에서는 쿼리를 사용하여 관련 도구 선택 집합을 선택하는 방법을 보여줍니다.
from llama_index.selectors.llm_selectors import ( LLMSingleSelector, LLMMultiSelector, ) from llama_index.selectors.pydantic_selectors import ( PydanticMultiSelector, PydanticSingleSelector, ) selector = LLMMultiSelector.from_defaults() from llama_index.tools.types import ToolMetadata tool_choices = [ ToolMetadata( name="covid_nyt", description=("This tool contains a NYT news article about COVID-19"), ), ToolMetadata( name="covid_wiki", description=("This tool contains the Wikipedia page about COVID-19"), ), ToolMetadata( name="covid_tesla", description=("This tool contains the Wikipedia page about apples"), ), ] selector_result = selector.select( tool_choices, query="Tell me more about COVID-19" ) selector_result.selections ''' [SingleSelection(index=0, reason='This tool contains a NYT news article about COVID-19'), SingleSelection(index=1, reason='This tool contains the Wikipedia page about COVID-19')] '''# Query Rewriting
이 섹션에서는 쿼리를 여러 쿼리로 재작성하는 방법을 보여드립니다. 그런 다음 검색기에 대해 이러한 모든 쿼리를 실행할 수 있습니다. 먼저 사용자가 지정한 프롬프트에 따라 쿼리를 재작성하는 예시 입니다.
from llama_index.prompts import PromptTemplate from llama_index.llms import OpenAI query_gen_str = """\ You are a helpful assistant that generates multiple search queries based on a \ single input query. Generate {num_queries} search queries, one on each line, \ related to the following input query: Query: {query} Queries: """ query_gen_prompt = PromptTemplate(query_gen_str) llm = OpenAI(model="gpt-3.5-turbo") def generate_queries(query: str, llm, num_queries: int = 4): response = llm.predict( query_gen_prompt, num_queries=num_queries, query=query ) # assume LLM proper put each query on a newline queries = response.split("\n") queries_str = "\n".join(queries) print(f"Generated queries:\n{queries_str}") return queries queries = generate_queries("What happened at Interleaf and Viaweb?", llm) """ Generated queries: 1. What were the major events or milestones in the history of Interleaf and Viaweb? 2. Who were the founders and key figures involved in the development of Interleaf and Viaweb? 3. What were the products or services offered by Interleaf and Viaweb? 4. Are there any notable success stories or failures associated with Interleaf and Viaweb? """다음은 LlamaIndex에 내장된 QueryTransform을 사용하는 방법 입니다. 쿼리에 대한 가상의 답변을 하는 HyDEQueryTransfom 입니다.
from llama_index.indices.query.query_transform import HyDEQueryTransform from llama_index.llms import OpenAI hyde = HyDEQueryTransform(include_original=True) llm = OpenAI(model="gpt-3.5-turbo") query_bundle = hyde.run("What is Bel?") # 생성된 HyDE 쿼리 """ ['Bel is a term that has multiple meanings and can be interpreted in various ways depending on the context. In ancient Mesopotamian mythology, Bel was a prominent deity and one of the chief gods of the Babylonian pantheon. He was often associated with the sky, storms, and fertility. Bel was considered to be the father of the gods and held great power and authority over the other deities.\n\nIn addition to its mythological significance, Bel is also a title that was used to address rulers and leaders in ancient Babylon. It was a term of respect and reverence, similar to the modern-day title of "king" or "emperor." The title of Bel was bestowed upon those who held significant political and military power, and it symbolized their authority and dominion over their subjects.\n\nFurthermore, Bel is also a common given name in various cultures around the world. It can be found in different forms and variations, such as Belinda, Isabel, or Bella. As a personal name, Bel often carries connotations of beauty, grace, and strength.\n\nIn summary, Bel can refer to a powerful deity in ancient Mesopotamian mythology, a title of respect for rulers and leaders, or a personal name with positive attributes. The meaning of Bel can vary depending on the specific context in which it is used.', 'What is Bel?'] """# Sub-Questions
도구 세트와 사용자 쿼리가 주어지면 1) 생성할 하위 질문 세트와 2) 각 하위 질문이 실행해야 하는 도구를 모두 결정합니다.
from llama_index.question_gen import ( LLMQuestionGenerator, OpenAIQuestionGenerator, ) from llama_index.llms import OpenAI from llama_index.tools.types import ToolMetadata from llama_index.schema import QueryBundle llm = OpenAI() question_gen = OpenAIQuestionGenerator.from_defaults(llm=llm) # OpenAIQuestionGenerator의 내장 프롬프트 확인 display_prompt_dict(question_gen.get_prompts()) """ You are a world class state of the art agent. You have access to multiple tools, each representing a different data source or API. Each of the tools has a name and a description, formatted as a JSON dictionary. The keys of the dictionary are the names of the tools and the values are the descriptions. Your purpose is to help answer a complex user question by generating a list of sub questions that can be answered by the tools. These are the guidelines you consider when completing your task: * Be as specific as possible * The sub questions should be relevant to the user question * The sub questions should be answerable by the tools provided * You can generate multiple sub questions for each tool * Tools must be specified by their name, not their description * You don't need to use a tool if you don't think it's relevant Output the list of sub questions by calling the SubQuestionList function. ## Tools ```json {tools_str} ``` ## User Question """ tool_choices = [ ToolMetadata( name="uber_2021_10k", description=( "Provides information about Uber financials for year 2021" ), ), ToolMetadata( name="lyft_2021_10k", description=( "Provides information about Lyft financials for year 2021" ), ), ] query_str = "Compare and contrast Uber and Lyft" choices = question_gen.generate(tool_choices, QueryBundle(query_str=query_str)) # choices 출력 """ [SubQuestion(sub_question='What are the financials of Uber for the year 2021?', tool_name='uber_2021_10k'), SubQuestion(sub_question='What are the financials of Lyft for the year 2021?', tool_name='lyft_2021_10k')] """# ReAct Prompt
초기 쿼리가 주어지면 1) 선택할 Tool과 2) 해당 Tool에서 실행할 쿼리를 식별합니다.
from llama_index.agent.react.formatter import ReActChatFormatter from llama_index.agent.react.output_parser import ReActOutputParser from llama_index.tools import FunctionTool from llama_index.core.llms.types import ChatMessage def execute_sql(sql: str) -> str: """Given a SQL input string, execute it.""" # NOTE: This is a mock function return f"Executed {sql}" def add(a: int, b: int) -> int: """Add two numbers.""" return a + b tool1 = FunctionTool.from_defaults(fn=execute_sql) tool2 = FunctionTool.from_defaults(fn=add) tools = [tool1, tool2] chat_formatter = ReActChatFormatter() output_parser = ReActOutputParser() input_msgs = chat_formatter.format( tools, [ ChatMessage( content="Can you find the top three rows from the table named `revenue_years`", role="user", ) ], ) # System prompt """ You are designed to help with a variety of tasks, from answering questions to providing summaries to other types of analyses. ## Tools You have access to a wide variety of tools. You are responsible for using the tools in any sequence you deem appropriate to complete the task at hand. This may require breaking the task into subtasks and using different tools to complete each subtask. You have access to the following tools: > Tool Name: execute_sql Tool Description: execute_sql(sql: str) -> str Given a SQL input string, execute it. Tool Args: {\'title\': \'execute_sql\', \'type\': \'object\', \'properties\': {\'sql\': {\'title\': \'Sql\', \'type\': \'string\'}}, \'required\': [\'sql\']} > Tool Name: add Tool Description: add(a: int, b: int) -> int Add two numbers. Tool Args: {\'title\': \'add\', \'type\': \'object\', \'properties\': {\'a\': {\'title\': \'A\', \'type\': \'integer\'}, \'b\': {\'title\': \'B\', \'type\': \'integer\'}}, \'required\': [\'a\', \'b\']} ## Output Format To answer the question, please use the following format. ``` Thought: I need to use a tool to help me answer the question. Action: tool name (one of execute_sql, add) if using a tool. Action Input: the input to the tool, in a JSON format representing the kwargs (e.g. {"input": "hello world", "num_beams": 5}) ``` Please ALWAYS start with a Thought. Please use a valid JSON format for the Action Input. Do NOT do this {\'input\': \'hello world\', \'num_beams\': 5}. If this format is used, the user will respond in the following format: ``` Observation: tool response ``` You should keep repeating the above format until you have enough information to answer the question without using any more tools. At that point, you MUST respond in the one of the following two formats: ``` Thought: I can answer without using any more tools. Answer: [your answer here] ``` ``` Thought: I cannot answer the question with the provided tools. Answer: Sorry, I cannot answer your query. ``` ## Current Conversation Below is the current conversation consisting of interleaving human and assistant messages. """ llm = OpenAI(model="gpt-4-1106-preview") response = llm.chat(input_msgs) reasoning_step = output_parser.parse(response.message.content) reasoning_step.action_input {'sql': 'SELECT * FROM revenue_years ORDER BY revenue DESC LIMIT 3'}○ Multi-Step Query Engine
우리는 복잡한 쿼리를 순차적인 하위 질문으로 분해할 수 있는 다단계 쿼리 엔진을 보유하고 있습니다.
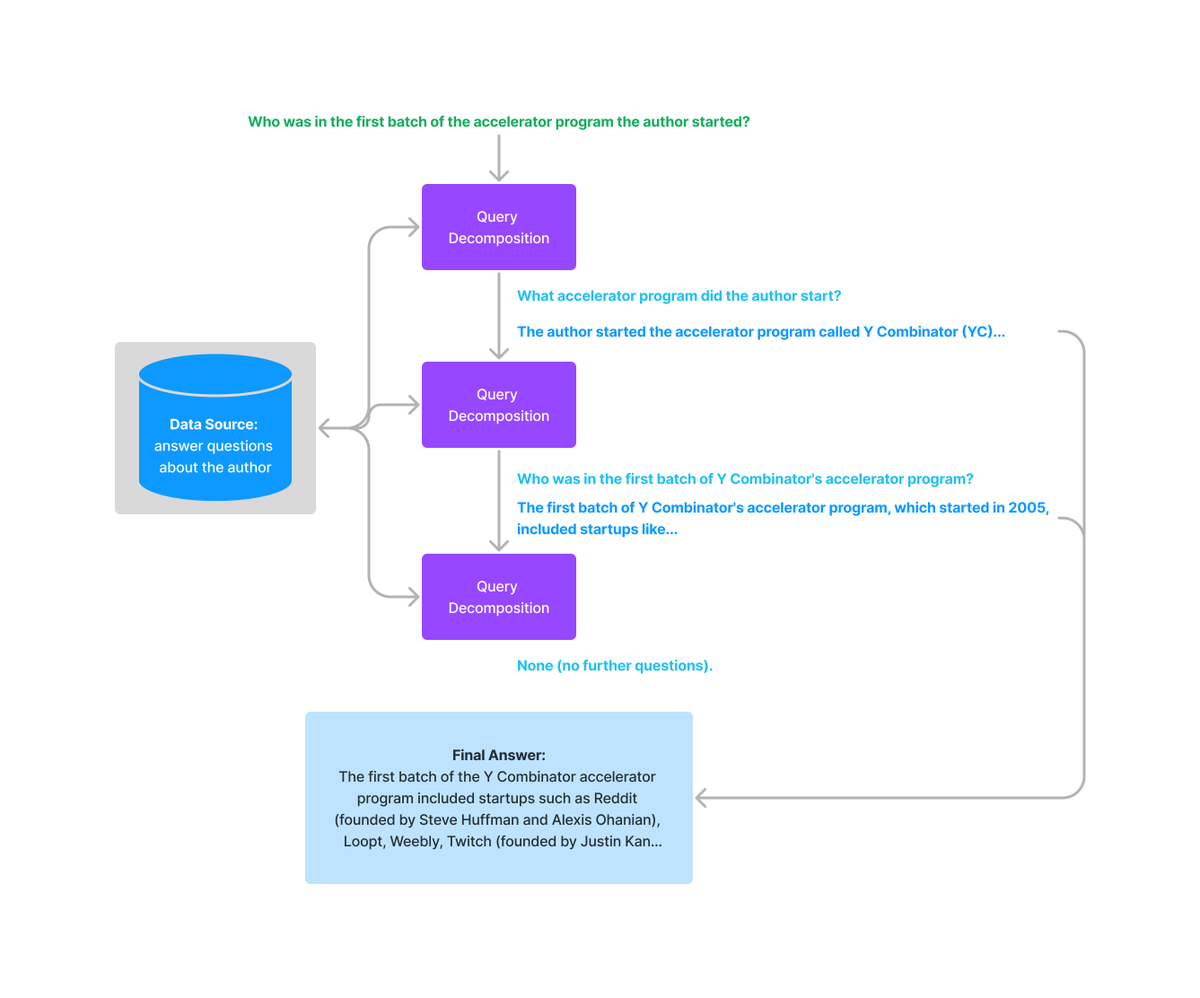
Multi-Step Querying Flow 아래 예시에서는 Multi-Step Query Engine을 구현하는 코드를 보여줍니다.
from llama_index.indices.query.query_transform.base import ( StepDecomposeQueryTransform, ) # gpt-4 step_decompose_transform = StepDecomposeQueryTransform(llm, verbose=True) query_engine = index.as_query_engine() query_engine = MultiStepQueryEngine( query_engine, query_transform=step_decompose_transform ) response = query_engine.query( "Who was in the first batch of the accelerator program the author started?", )○ Deep Memory
RAG의 성능 개선을 위해 작은 신경망(Deep Memory)을 구성하고 Chunk와 쿼리의 관련도를 학습시켜 답변의 품질을 개선할 수 있습니다. 학습된 Deep Memory는 벡터 검색 정확도를 최대 +22%까지 크게 높입니다.

다음은 Deep Memory 훈련과 적용을 위해 chunk가 레이블링된 데이터셋을 구축하고 학습하는 과정을 보여주는 코드입니다.
from llama_index.evaluation import ( generate_question_context_pairs, EmbeddingQAFinetuneDataset, ) import random def create_train_test_datasets( number_of_samples=600, llm=None, nodes=None, save=False ): random_indices = random.sample(range(len(nodes)), number_of_samples) ratio = int(len(random_indices) * 0.8) train_indices = random_indices[:ratio] test_indices = random_indices[ratio:] train_nodes = [nodes[i] for i in train_indices] test_nodes = [nodes[i] for i in test_indices] train_qa_dataset = generate_question_context_pairs( train_nodes, llm=llm, num_questions_per_chunk=1 ) test_qa_dataset = generate_question_context_pairs( test_nodes, llm=llm, num_questions_per_chunk=1 ) # [optional] save if save: train_qa_dataset.save_json( f"deeplake_docs_{number_of_samples}_train.json" ) test_qa_dataset.save_json( f"deeplake_docs_{number_of_samples}_test.json" ) return train_qa_dataset, test_qa_dataset train_qa_dataset, test_qa_dataset = create_train_test_datasets( number_of_samples=600, llm=llm, nodes=nodes, save=True ) train_qa_dataset = EmbeddingQAFinetuneDataset.from_json( "deeplake_docs_600_train.json" ) test_qa_dataset = EmbeddingQAFinetuneDataset.from_json( "deeplake_docs_600_test.json" ) def create_query_relevance(qa_dataset): """Function for converting llama-index dataset to correct format for deep memory training""" queries = [text for _, text in qa_dataset.queries.items()] relevant_docs = qa_dataset.relevant_docs relevance = [] for doc in relevant_docs: relevance.append([(relevant_docs[doc][0], 1)]) return queries, relevance train_queries, train_relevance = create_query_relevance(train_qa_dataset) test_queries, test_relevance = create_query_relevance(test_qa_dataset) from langchain.embeddings.openai import OpenAIEmbeddings embeddings = OpenAIEmbeddings() job_id = vector_store.vectorstore.deep_memory.train( queries=train_queries, relevance=train_relevance, embedding_function=embeddings.embed_documents, )다음은 학습된 Deep Memory를 통해 추론하는 코드입니다.
query_engine = vector_index.as_query_engine( vector_store_kwargs={"deep_memory": True} ) response = query_engine.query( "How can you connect your own storage to the deeplake?" ) print(response)# Deep Memory 관련 자료
https://www.activeloop.ai/resources/use-deep-memory-to-boost-rag-apps-accuracy-by-up-to-22/https://docs.activeloop.ai/high-performance-features/deep-memory