-
[LlamaIndex] Building RAG Applications for Production카테고리 없음 2024. 2. 6. 22:45
RAG 애플리케이션의 프로토타입을 만드는 것은 쉽지만 성능이 뛰어나고 강력하며 대규모 지식 자료로 확장 가능하도록 만드는 것은 어렵습니다. 이 가이드에는 RAG 파이프라인의 성능을 향상시키기 위한 다양한 팁과 요령이 포함되어 있습니다. 먼저 몇 가지 일반적인 기술의 개요와 구현방법을 설명합니다. 가장 간단한 기술부터 가장 어려운 기술까지 있습니다. 최종 목표는 검색 및 생성 성능을 최적화하여 더 복잡한 데이터 세트에 대한 더 많은 쿼리에 환각 없이 정확하고 답변하는 것입니다.
○ 검색된 Chunk와 응답 합성에 사용되는 Chunk 분리하여 생각하기
더 나은 검색을 위한 핵심 기술은 검색에 사용되는 Chunk를 합성에 사용되는 Chunk와 분리하는 것입니다

# 문서와 관련된 청크로 연결되는 문서 요약 삽입
이렇게 하면 청크를 직접 검색하는 것보다 청크를 검색하기 전에 개략적인 수준에서 관련 문서를 검색하는 데 도움이 됩니다.
문서 요약 인덱스는 각 문서에서 요약을 추출하고 해당 요약과 문서에 해당하는 모든 노드를 저장합니다.검색은 LLM 또는 임베딩을 통해 수행될 수 있습니다. 먼저 요약을 기반으로 쿼리와 관련된 문서를 선택합니다. 선택한 문서에 해당하는 모든 검색된 노드가 검색됩니다.
# default mode of building the index response_synthesizer = get_response_synthesizer( response_mode="tree_summarize", use_async=True ) doc_summary_index = DocumentSummaryIndex.from_documents( city_docs, service_context=service_context, response_synthesizer=response_synthesizer, show_progress=True, ) query_engine = doc_summary_index.as_query_engine( response_mode="tree_summarize", use_async=True ) response = query_engine.query("What are the sports teams in Toronto?")# 문장 주변의 창으로 연결되는 문장 삽입
문맥을 더 세밀하게 검색할 수 있을 뿐만 아니라 LLM 합성을 위한 충분한 문맥을 확보할 수 있습니다.
# create the sentence window node parser w/ default settings node_parser = SentenceWindowNodeParser.from_defaults( window_size=3, window_metadata_key="window", original_text_metadata_key="original_text", )○ 더 큰 문서 세트에 대한 구조적 검색
기본 RAG의 큰 문제는 문서 수가 증가함에 따라 제대로 작동하지 않는다는 것입니다. 이 설정에서는 쿼리가 제공되면 구조화된 정보를 사용하여 보다 정확한 검색을 수행할 수 있습니다.

# 메타데이터 필터 + 자동 검색
메타데이터로 각 문서에 태그를 지정한 다음 벡터 데이터베이스에 저장합니다. 추론 시간 동안 LLM을 사용하여 의미론적 쿼리 문자열 외에도 벡터 db를 쿼리하기 위한 올바른 메타데이터 필터를 추론합니다.
- 장점 ✅: 주요 벡터 DB에서 지원됩니다. 여러 차원을 통해 문서를 필터링할 수 있습니다.
- 단점 🚫: 올바른 태그를 정의하기 어려울 수 있습니다. 태그에는 보다 정확한 검색을 위한 충분한 관련 정보가 포함되어 있지 않을 수 있습니다. 또한 태그는 문서 수준의 키워드 검색을 나타내며 의미 체계 조회를 허용하지 않습니다.
from llama_index.indices.vector_store.retrievers import ( VectorIndexAutoRetriever, ) from llama_index.vector_stores.types import MetadataInfo, VectorStoreInfo vector_store_info = VectorStoreInfo( content_info="brief biography of celebrities", metadata_info=[ MetadataInfo( name="category", type="str", description=( "Category of the celebrity, one of [Sports, Entertainment," " Business, Music]" ), ), MetadataInfo( name="country", type="str", description=( "Country of the celebrity, one of [United States, Barbados," " Portugal]" ), ), ], ) retriever = VectorIndexAutoRetriever( index, vector_store_info=vector_store_info, service_context=service_context, max_top_k=10000, ) nodes = retriever.retrieve("Tell me about the childhood of a UK billionaire") for node in nodes: print(node.node.get_content())# 문서 계층 구조 저장(요약 -> 원시 청크) + 재귀 검색
문서 요약을 포함하고 문서당 청크로 매핑합니다. 청크 수준 이전에 문서 수준에서 먼저 가져옵니다.
- 장점 ✅: 문서 수준에서 의미 체계 조회가 가능합니다.
- 단점 🚫: 구조화된 태그로 키워드 조회를 허용하지 않습니다(의미론적 검색보다 더 정확할 수 있음). 또한 자동 생성 요약은 비용이 많이 들 수 있습니다.
○ 작업에 따라 동적으로 청크 검색
RAG는 단지 Top-K 유사성이 최적화된 특정 사실에 대한 질문 답변이 아닙니다. 사용자가 물어볼 수 있는 쿼리는 다양할 수 있습니다. 순진한 RAG 스택이 처리하는 쿼리에는 "2023년 이 회사의 D&I 이니셔티브에 대해 알려주세요" 또는 "내레이터가 Google에 근무하는 동안 무엇을 했나요?"와 같은 특정 사실에 대해 묻는 쿼리가 포함됩니다. 그러나 쿼리에는 "이 문서에 대한 높은 수준의 개요를 제공할 수 있습니까?" 또는 "X와 Y를 비교/대조할 수 있습니까?"와 같은 요약이 포함될 수도 있습니다. 이러한 모든 사용 사례에는 서로 다른 검색 기술이 필요할 수 있습니다.
# Sub Question Query Engine
Sub Question Query Engin은 복잡한 쿼리를 각 관련 데이터 소스에 대한 하위 질문으로 나눈 다음 모든 중간 응답을 수집하고 최종 응답을 종합합니다.
# setup base query engine as tool query_engine_tools = [ QueryEngineTool( query_engine=vector_query_engine, metadata=ToolMetadata( name="pg_essay", description="Paul Graham essay on What I Worked On", ), ), ] query_engine = SubQuestionQueryEngine.from_defaults( query_engine_tools=query_engine_tools, service_context=service_context, use_async=True, ) response = query_engine.query( "How was Paul Grahams life different before, during, and after YC?" )Generated 3 sub questions. [pg_essay] Q: What did Paul Graham do before YC? [pg_essay] Q: What did Paul Graham do during YC? [pg_essay] Q: What did Paul Graham do after YC? [pg_essay] A: Before YC, Paul Graham was a hacker, writer, and worked on Arc, a programming language. He also wrote essays and worked on other projects. [pg_essay] A: Paul Graham stopped working on YC in March 2014 and began painting. He spent most of the rest of the year painting and then in November he ran out of steam and stopped. He then began writing essays again and in March 2015 he started working on Lisp again. [pg_essay] A: Paul Graham worked on YC in a variety of ways. He wrote essays, worked on internal software in Arc, and created Hacker News. He also helped select and support founders, dealt with disputes between cofounders, and fought with people who maltreated the startups. He worked hard even at the parts he didn't like, and was determined to make YC a success. In 2010, he was offered unsolicited advice to make sure YC wasn't the last cool thing he did, which set him thinking about his future. In 2012, he decided to hand YC over to someone else and recruited Sam Altman to take over. He worked on YC until March 2014, when his mother passed away, and then he checked out completely.# Router Query Engine
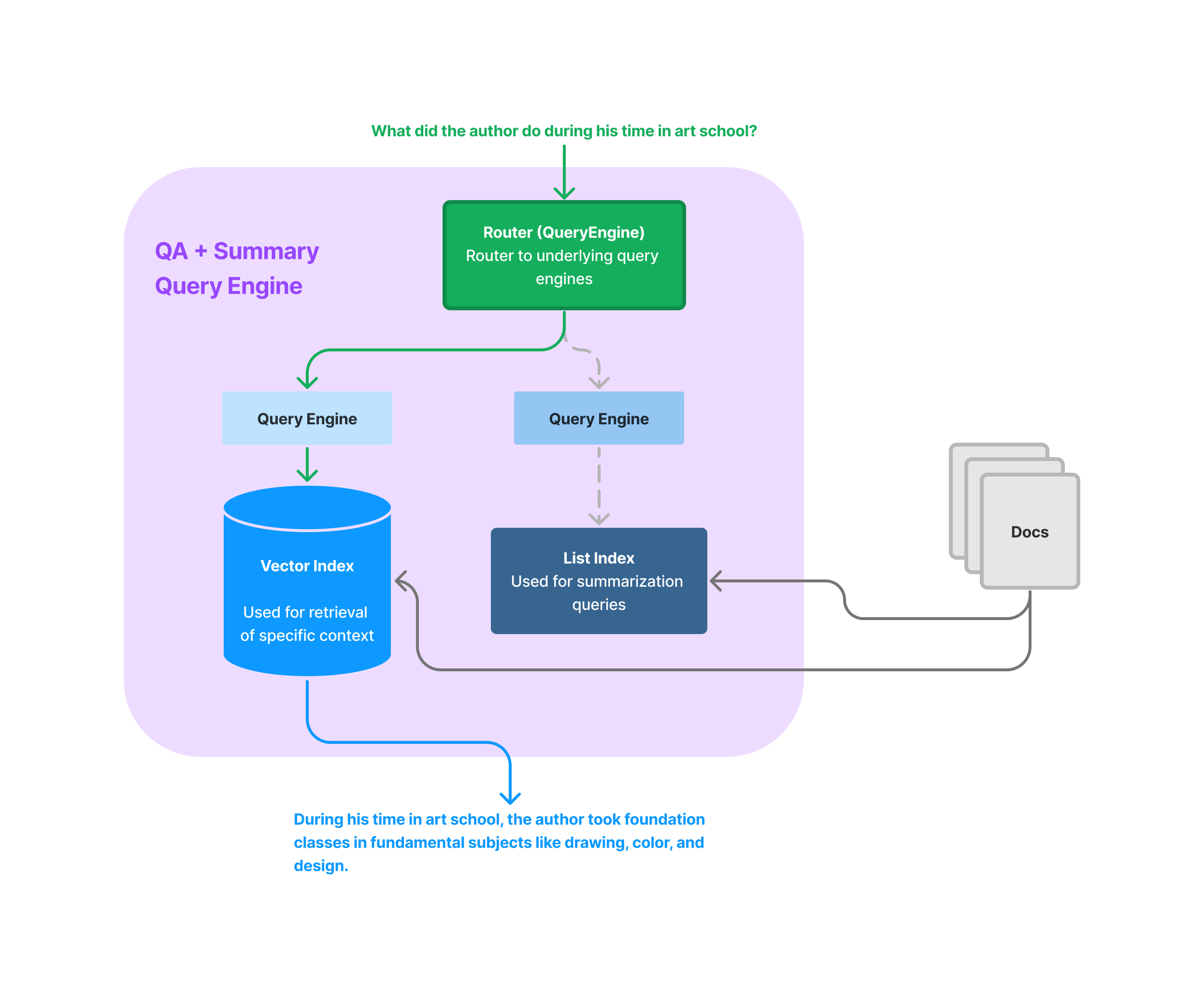
Router Query Engin을 사용하면 쿼리를 실행하기 위해 여러 후보 쿼리 엔진 중 사용자 질의에 적합한 쿼리엔진을 선택할 수 있습니다.
from llama_index.tools.query_engine import QueryEngineTool list_tool = QueryEngineTool.from_defaults( query_engine=list_query_engine, description=( "Useful for summarization questions related to Paul Graham eassy on" " What I Worked On." ), ) vector_tool = QueryEngineTool.from_defaults( query_engine=vector_query_engine, description=( "Useful for retrieving specific context from Paul Graham essay on What" " I Worked On." ), ) query_engine = RouterQueryEngine( selector=LLMSingleSelector.from_defaults(), query_engine_tools=[ list_tool, vector_tool, ], ) response = query_engine.query("What is the summary of the document?") print(str(response))