-
[논문리뷰] Retrieval Augmented Generation for Knowledge Intensive NLP Tasks(2020)카테고리 없음 2024. 3. 27. 13:33
# 요약
Large pre-trained model은 사실적 지식을 매개변수에 저장하고, 다운스트림 NLP 작업에서 미세 조정할 때 SOTA의 성능을 냄. 그러나 지식에 접근하고 정확하게 다루는데는 여전히 한계가 있음. 또한 결과에 대한 출처를 제공하고 지식을 업데이트하는 것도 한계가 있음.
본 논문에서는 Language model의 parametric memory에 non-parametric memory를 결합한 RAG(Retrival-augmented generation)을 제안함. Parametric memory는 pre-trained seq2seq 모델을 사용하고, non-parametric memory로 pre-trained neural retriever로 위키피디아의 dense vector를 사용. 광범위한 지식 집약적 NLP 작업에서 모델을 미세 조정하고 평가하며, 세 가지 오픈 도메인 QA 작업에서 기존의 모델들 보다 뛰어난 성능을 보임.
# 도입
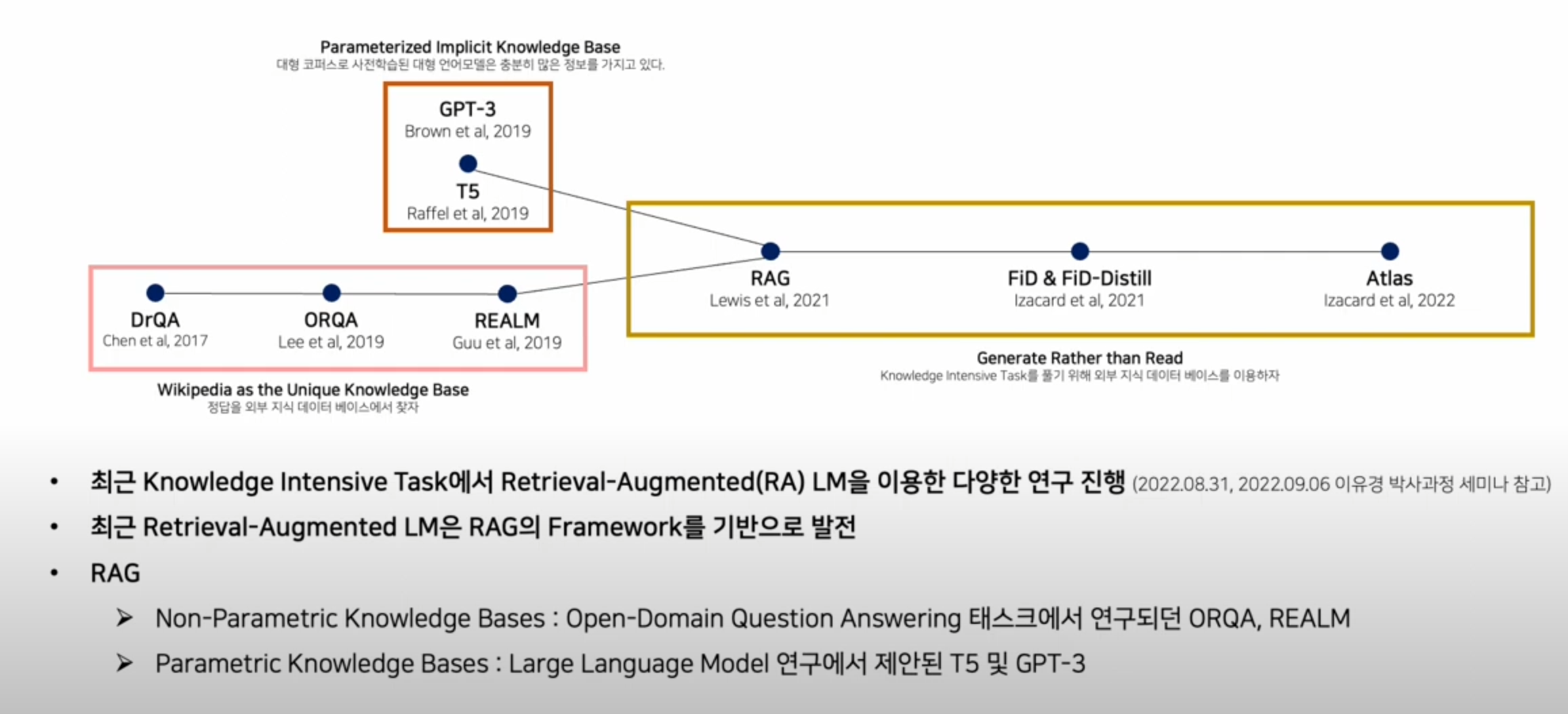
- 사전 학습된 언어 모델은 매개변수화된 지식 베이스로서 외부 메모리에 대한 액세스 없이도 학습된 지식을 사용 할 수 있음
- But 메모리 확장/수정이 어렵고, 예측결과에 대한 통찰력을 제공할 수 없으며, '환각'(Hallucination)이 있음
- parametric memory에 non-parametric memory(검색 기반)를 결합한 하이브리드 모델은 지식을 직접 수정 및 확장할 수 있고 접근한 지식을 검사하고 해석할 수 있기 때문에 이러한 문제를 해결할 수 있음.
- Parametric memory 는 사전 학습된 seq2seq, non-parametric memory는 사전 학습된 뉴럴 리트리버로 액세스되는 Wikipedia의 고밀도 벡터 인덱스- 리트리버(DPR)는 입력에 따라 조건이 지정된 잠재 문서를 제공, seq2seq 모델은 입력과 함께 이러한 잠재 문서를 조건화하여 출력을 생성
- RAG는 Open Natural Questions, WebQuestions and CuratedTree 등 에서 SOTA를 달성
- RAG 논문 이전과 이후에도 Open-Domain Question Answering 태스크의 연구는 지속되어 왔으나, Prameterized Knowledge Base(PLM)과 Non-Parametric Knowledge Base를 결합한 하이브리드 방법을 최초로 제안 했다는 점에서 의의가 있음
출처: https://www.youtube.com/watch?v=gtOdvAQk6YU, 고려대학교 산업경영공학부 DSBA 연구실 유튜브 
# 제안
- RAG는 검색기와 생성기로 구성
- 검색기 : 쿼리에 대해 유사성이 높은 top-k의 텍스트 구절을 반환(Non-parametric)
- 생성기 : 검색된 구절을 기반으로 응답 토큰을 생성(Parametric)
- RAG-Sequence와 RAG-Token의 두가지 방법을 제안
## RAG-Sequence : 모델이 동일한 문서를 사용해 각 대상 토큰을 예측후 가중합(Maginalize)
- 리트리버를 통해 Top k 문서를 검색하고, 각 문서에 대한 시퀀스 아웃풋 y을 생성\
- 각각의 시퀀스 아웃풋 y의 확률은 유사도 점수(document vector와 query x vector간의 내적값)로 가중합 적용

출처: https://www.youtube.com/watch?v=efoqG3Hg0Ng ## RAG-Token : 다른 문서를 기반으로 각각의 다음 토큰을 예측
- 각 토큰 예측 시 다른 문서를 retreive함녀서 시퀀스 아웃풋 y를 생성

출처: https://www.youtube.com/watch?v=efoqG3Hg0Ng ## Retriever: DPR
- BERT_base 모델로 bi-encoder 방식으로 쿼리와 문서를 임베딩
- 임베딩 벡터 내적값을 통해 쿼리와 가장 유사성이 높은 문서 Top-k개를 검색
## Generator: BART
- BART-large(Parameter o.4B) 모델에 쿼리와 검색된 Top-k 문서를 연결하여 답변 생성
## Training
- 문서 인코더(및 인덱스)는 고정된 상태로 유지하고 쿼리 인코더 BERTq와 BART 생성기만 미세 조정합니다.
- 문서 인코더를 미세조정 하지 않는 이유는 비용대비 효과가 크지 않음
# 결과

## Open-domain Question Answering
- 4개 분야에서 모두 SOTA 달성(Table1)- BERT 기반 Cross Encoder를 사용하여 문서 순위를 재조정하는 DPR QA 시스템과 비교해도 우수한 성능 나타냄
- 즉, SOTA 성능을 위해 Re-rank가 굳이 필요하지 않다는 것을 보여줌
## Abstractive Question Answering
- MS-MARCO LNG 벤치마크에서 BART보다 우수(Table2)- 답변 품질로 볼때, RAG 모델이 환각이 더 적고, 정확한 텍스트럴 더 자주 생성
## Jeopardy Question Generation
- 전반적으로 BART 대비 우수함- RAG-Token이 RAG-Sequence보다 더 나음
- Human evaluation에서는 BART보다 RAG가 더 사실적이라고 답함(42.7% vs 7.1%)
## Fact Verification
- 전반적으로 BART 대비 우수함- 현재 SOTA 모델 대비는 성능이 떨어짐
- SOTA 모델은 도메인 맞춤 엔지니어링과 리트리버의 지도학습이 적용되었으나, RAG는 필요하지 않음(비용 효율적)
## Retrieval Ablations
- 전반적으로 DPR Retriever를 학습한 경우, 성능이 좋았음
- FEVER 벤치마크에서는 BM25(word overlap-based retriever)의 성능이 좋음
- 이는 해당 데이터셋이 엔티티 중심이라서 해당 Task에 BM25가 더 적합하기 때문

# 참고한 자료
https://arxiv.org/abs/2005.11401
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still lim
arxiv.org
https://www.youtube.com/watch?v=gtOdvAQk6YU
https://blog.naver.com/gypsi12/223318524994
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks [ arXiv 2021.04.12 ]
논문 [ 링크 ] Abstract LLM이 parameter 안에 fatual knowledge를 가지고 있는 것처럼 보인다 하지만,...
blog.naver.com
https://www.youtube.com/watch?v=efoqG3Hg0Ng
https://velog.io/@tobigs-nlp/Retrieval-Augmented-Generation-for-Knowledge-Intensive-NLP-Tasks
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
내가 새로운 정보를 반영해볼게! | 장준원
velog.io