-
[논문리뷰] Corrective Retrieval Augmented Generation(CRAG, 2024)카테고리 없음 2024. 4. 4. 12:23
1. 요약
- 검색 증강 생성(RAG)은 LLM의 할루시네이션을 보완할 수 있지만 검색된 문서에 크게 의존
- RAG의 답변 품질을 개선하기 위해 수정 검색 증강 생성(CRAG)을 제안
- Retrieval evaluator를 통해 쿼리에 대해 검색된 문서의 전반적인 품질을 평가
- 검색된 문서의 정보가 불충분한 경우, 대규모 웹 검색을 통해 검색 결과를 보강
- 검색된 문서가 핵심 정보에 선택적으로 집중하고 관련 없는 정보를 걸러낼 수 있도록 분해 후 재구성
- CRAG는 플러그 앤 플레이 방식으로 다양한 RAG에 쉽게 결합 가능
- 다양한 데이터 세트에 대한 실험 결과, CRAG가 기존 RAG 대비 성능이 우수함
2. 인트로
- 검색 증강 생성(RAG)은 LLM의 할루시네이션을 보완할 수 있지만 검색된 문서의 관련성과 정확성에 크게 의존
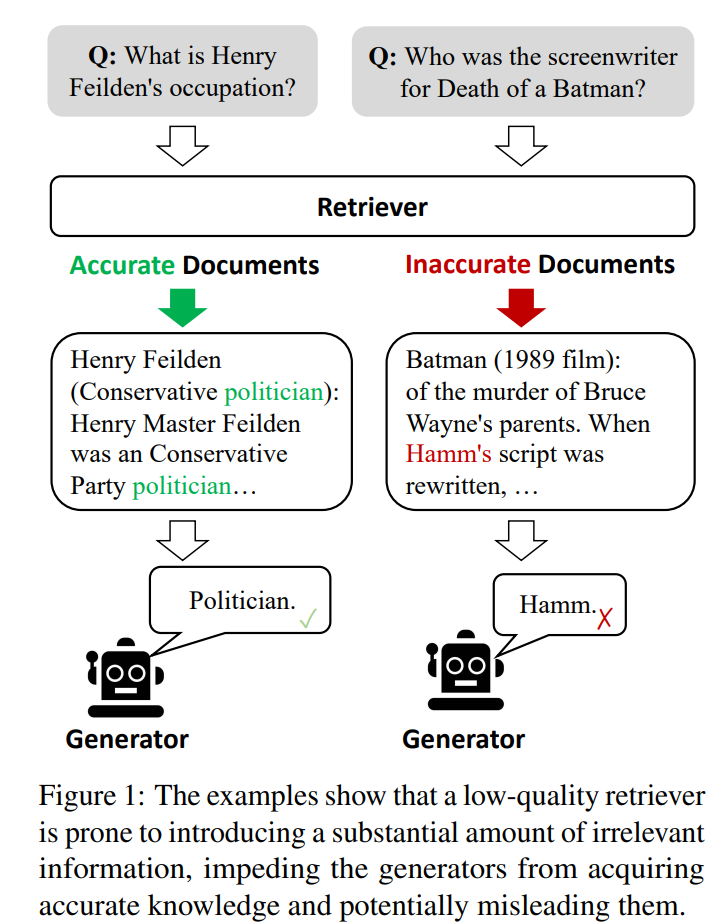
- 품질이 낮은 검색기는 상당한 양의 관련 없는 정보를 가져오며, LLM이 정확한 지식을 습득하는 데 방해가 됨
- 기존 RAG 는 검색된 문서의 관련성 여부에 관계없이 무차별적으로 통합함(Figure1 참조)
- CRAG(Corrective Retrieval-Augmented Generation) : 검색 결과를 스스로 수정하고 증강 생성된 문서의 활용도를 높임
- Retrieval evaluator로 쿼리에 대해 검색된 문서의 관련성과 신뢰도를 평가
- 신뢰도는 {정답, 부정확, 모호}으로 평가되며, 부정확, 모호에 해당될 경우, 대규모 웹 검색 실시
- 검색된 문서에서 RAG에 도움이 되지 않는 컨텍스트를 제거하기 위해 검색 및 활용 프로세스 전반에 걸쳐 분해 후 재구성
- CRAG는 Plug-and-Play 방식으로 기존 RAG에 연동 가능함
- PopQA, Biography, Pub Health, Arc-Challenge의 4개 데이터 세트에 테스트 결과 표준 RAG와 최첨단 Self-RAG의 성능을 크게 향상시킴
3. 제안
3.1 Background - RAG Formulation
- P (Y|X ) = P(D|X )P(Y, D|X )
- 입력 X와 대량의 지식 문서 C = {d1, ..., dN }가 주어졌을때 출력 Y를 생성
- 리트리버 R은 코퍼스 C에서 입력 X와 관련된 상위 K 문서 D = {dr1 , ..., drk }를 검색
- 입력 X와 검색된 결과 D에 따라 생성기 G가 출력 Y를 생성
- 검색된 결과가 출력 Y의 품질에 크게 영향
3.2 CRAG(Corrective Retrieval Augmented Generation)
3.2.1 Overview of Model Inference
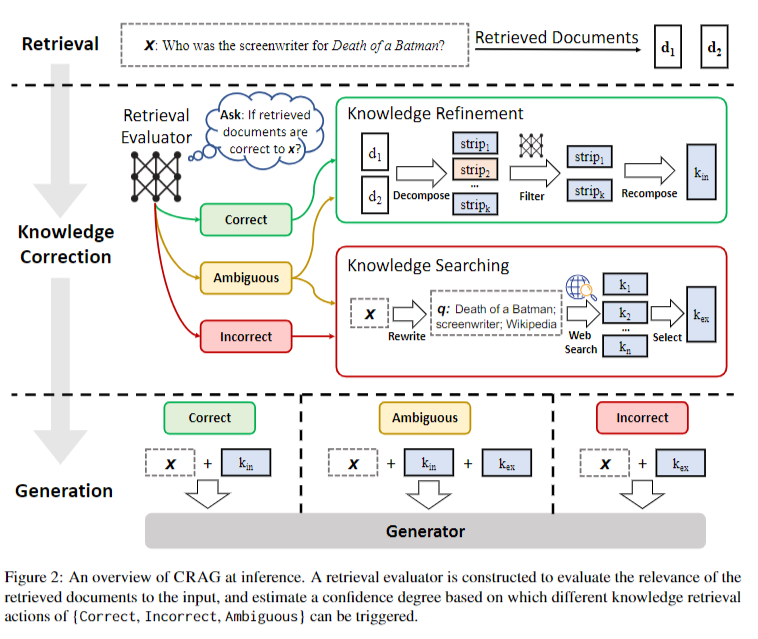
- Retrieval evaluator로 검색된 문서와 입력 쿼리의 관련성을 평가
- 관련성은 세 단계로 평가(정답, 부정확, 모호)되며 평가 결과에 따라 각각 다른 Action을 실시
①Correct(정답) => 검색된 문서를 더 정확한 지식으로 정제(Knowledge Refinement)
②Incorrect(부정확) => 검색된 문서 제거 후 웹 검색을 통해 지식 증강(Web Search)
③Ambiguous(모호) => 검색 결과 정제 및 웹 검색 둘다 실행

3.2.2 Retrieval Evaluator
- PopQA 등의 데이터셋으로 T5-large를 Fine-tuning하여 Retrieval evaluator 모델 구성
- Self-RAG의 평가모델(LLaMA-2, 7B) 대비 매우 가벼움(0.77B)
3.2.3 Knowledge Refinement
- 검색된 관련 문서가 주어지면, 몇 문장 수준의 작은 단위로 다시 나눔
- 나눠진 단위(strip)은 Retrieval evaluator로 관련성을 평가하며, 관련성이 낮은 지식을 제거하여 더 정확한 지식으로 정제
3.2.4 Web Search
- 검색된 결과가 모두 관련성이 없는 경우 웹 검색 실행
- 웹 검색은 Google Search API 사용하며, 위키피디아를 우선적으로 검색
- GPT 3.5를 사용하여 입력 쿼리 내용을 웹검색을 위한 검색 쿼리(키워드)로 재작성 (Table 5 참고)
- 키워드로 검색된 웹 페이지를 탐색하며 Knowledge Refinement 방법으로 관련된 웹 지식을 도출

4. 결과
- PopQA, Biography, PubHealth, Arc-Challenge 데이터셋으로 검증
- RAG와 Self-RAG에 CRAG 적용전과 후를 비교하는 방식으로 테스트
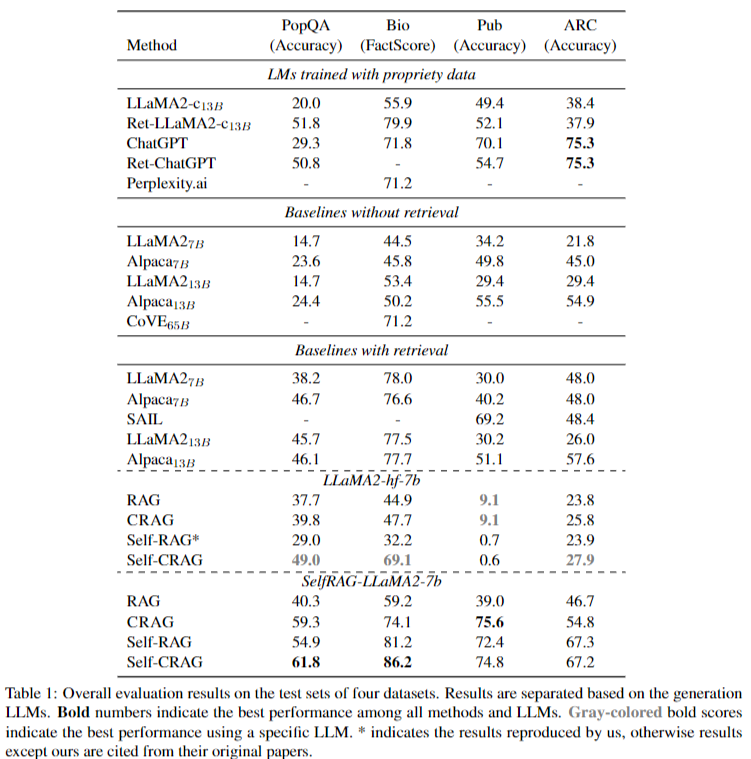
- CRAG 적용시 성능 크게 향상(Table 1)
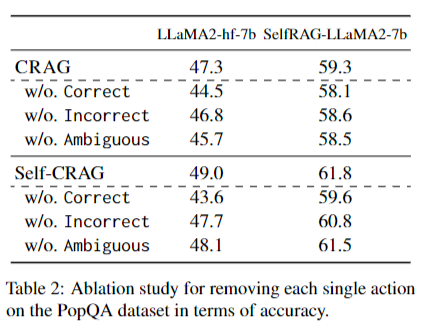
- Retrieval evaluator의 평가 결과별 Action의 효과에 대해 검증하기 위해 각 액션을 제거한 후 성능검증 결과 하나의 액션이라도 제거시 성능이 저하됨 => 모든 액션이 성능 개선에 기여함을 확인(Table 2)
- Knowledge Refinement , 검색 쿼리 재작성, 외부 지식 선택의 작업을 개별적으로 제거하여 성능 검증
=> 각 지식 활용 작업이 지식의 활용도를 높이는 데 기여했음을 확인(Table 3)
- Retrieval evaluator의 품질에 따른 답변 성능 검증을 위해 본 논문에서 적용된 T5-based Model과 ChatGPT, ChatGPT-CoT 및 ChatGPT-fewshot을 비교함 => T5-based Retrieval evaluator의 성능이 가장 우수

5. 한계점
- 잘못된 지식을 정확하고 효과적으로 감지하고 수정하는 다양한 방법에 대해 추가 연구 필요
- CRAG은 Retrieval evaluator를 반드시 Fine-tuning 해야하는 단점이 있음
- 웹 검색 결과의 잠재적 편향으로 인해 출력에 노이즈가 발생하거나 잘못된 정보가 포함되는 위험 존재
# 참고한 자료
https://arxiv.org/abs/2401.15884
Corrective Retrieval Augmented Generation
Large language models (LLMs) inevitably exhibit hallucinations since the accuracy of generated texts cannot be secured solely by the parametric knowledge they encapsulate. Although retrieval-augmented generation (RAG) is a practicable complement to LLMs, i
arxiv.org