-
[논문리뷰] Adaptive-RAG: Learning to Adapt Retrieval-AugmentedLarge Language Models through Question Complexity카테고리 없음 2024. 4. 12. 23:21
1. 요약
- 외부 지식을 LLM에 통합하는 RAG는 다양한 Task에서 활용됨
- 그러나 복잡한 쿼리를 적절히 처리 못하거나, 단순한 쿼리 처리에 불필요한 계산량을 소비하는 문제 발생
- 쿼리의 복잡도에 따라 가장 적합한 전략을 동적으로 선택할 수 있는 적응형 QA 프레임워크 Adaptive-RAG를 제안
- Adaptive-RAG는 쿼리 처리 전에 분류 모델을 통해 쿼리의 복잡도 수준을 판별- 판별된 쿼리 복잡도에 따라 비 검색, 단일 단계 검색, 복잡한 처리 등을 수행
2. 도입
- 매개변수화된 지식에만 의존하는 LLM의 한계를 개선하기 위해 검색 증강 LLM이 많이 사용됨
- 검색 증강 LLM은 사용자 쿼리, 특히 복잡도가 높은 쿼리에 대해 답을 제공하는 Task에 많이 사용됨
- 복잡도가 높은 쿼리는 여러 문서와의 연결과 결과 집계가 필요하는 등 단순 검색 및 응답으로 답변이 안됨
- 복잡한 쿼리를 효과적으로 처리하기 위해 최근 다단계 및 다중 추론 QA가 연구되고 있으나, 많은 계산비용이 요구됨
- 다단계 QA 접근 방식은 복잡한 쿼리에는 필수적이지만 단순한 쿼리에는 불필요한 계산비용이 발생함
- 즉, 쿼리 복잡도에 따라 RAG 실행 전략을 동적으로 조정하는 적응형 QA 시스템이 필요
- Adaptive-RAG는 쿼리의 복잡도를 분류하는 Classifier(훈련된 Small LM)를 추가
- 예측된 쿼리 복잡도에 따라 Non Retrieval QA , Single-step Approach for QA, Multi-step Approach for QA를 수행
- Open-domain QA datasets에서 기존의 적응 전략 대비 정확도와 효율성이 향상됨

3. 제안 (Adaptive-RAG)
- 쿼리 복잡도에 따라 3단계 전략으로 대응
[직관적 쿼리] -> Non Retrieval QA : 외부 문서를 참조하지 않고, LLM 자체에서 답변[단순 쿼리] -> Single-step Approach for QA : 1차 검색을 통해 외부 소스 정보 활용
[복잡 쿼리] -> Multi-step Approach for QA : n차 검색/추론을 통해 여러 소스 정보를 종합하고 추론
- 쿼리의 복잡도 측정을 위해 작은 언어모델을 학습시켜 복잡도 분류기를 만듬
- 분류기 학습을 위한 데이터셋은 아래와 같은 방법으로 구축함
1) QA 벤치마크 데이터셋을 준비한 후, 각 데이터포인트에 3단계 대응 전략을 적용한 결과를 기반으로 라벨링을 함
ex) Non Retrieval QA로 정답을 생성하면 쿼리 복잡도는 '직관적' 으로 라벨링함
2) 두개 이상의 대응 전략이 올바르게 작동했을 경우, 더 단순한 전략의 라벨링을 적용
ex) Single-step Approach for QA와 Multi-step Approach for QA 모두 정답 생성시 '단순'으로 라벨링
3) 3가지 전략 모두 실패했을 경우, 벤치마크 데이터셋의 종류에 따라 라벨링함
ex) Single-hop 데이터셋*의 쿼리는 '단순', Multi-hop 데이터셋** 쿼리는 '복잡'*Single-hop 데이터셋: 쿼리와 관련 답변이 포함된 관련 문서로 구성된 데이터 세트. SQuAD v1.1, Natural Questions, TriviaQA
**Multi-hop 데이터셋: 여러 문서에 대한 순차적 추론이 필요한 데이터세트. MuSiQue, HotpotQA, 2WikiMultiHopQA4. 평가
4.1. Dataset
- Single-hop 데이터셋과 Multi-hop 데이터셋에 대해 테스트
4.2 비교 모델(전략)
- No Re-trieva: LLM만 사용하여 주어진 쿼리에 대한 답을 생성합니다.
- Single-step Approach: 외부 지식 소스에서 관련 지식을 검색하여 정보 증강 후 LLM으로 답을 생성. 한번만 수행- Adaptive Retrieval: 쿼리에 존재하는 엔티티가 덜 유명한 경우에만 검색 모듈로 정보를 증강 후 LLM으로 답 생성
- Self-RAG: LLM이 검색과 생성을 적응적 수행하도록 훈련시켜 필요시 검색을 수행하고 답변을 생성
- Multi-step Approach: 다단계 검색 증강 LLM으로, 해를 도출하거나 최대 단계 수에 도달할 때까지 검색/추론을 반복
- Adaptive-RAG: 쿼리 복잡도에 따라 3단계의 적응형 방법으로 답변 생성
- Adaptive-RAG w/Oracle: Adaptive-RAG의 쿼리 복잡도 평가가 완벽하게 동작하는 시나리오
4.3 평가 지표
- 효과와 효율을 모두 평가함
- 효과 지표
1) F1 : 예측된 답변과 근거 진실 간의 중복 단어 수
2) EM : 동일 여부
3) 정확도 : 예측된 답변에 진실 답변이 포함되어 있는지 여부
- 효율 지표(one-step approach와 비교하여 측정)
4) 검색/생성 단계의 수
5) 각 쿼리에 대한 평균 답변 시간4.4 결과
- 모든 모델 결과를 종합해보면, 복잡한 검색 증강 전략은 단순한 전략보다 효과는 좋지만, 효율이 떨어짐(Cost가 비쌈)
=> 따라서 적응형 전략이 필요- Adaptive-RAG는 다른 적응형 전략(Adaptive Retrieval, Self-RAG) 대비 더 좋은 효과를 보임
- Adaptive-RAG는 다른 복잡한 전략(Multi-step Approach) 대비 더 효율적임
- Adaptive-RAG w/Oracle의 경우 Adaptive-RAG보다 좋은 효과와 효율을 보임
=> 최적의 성능을 위해서는 쿼리 복잡도의 분류기 성능이 중요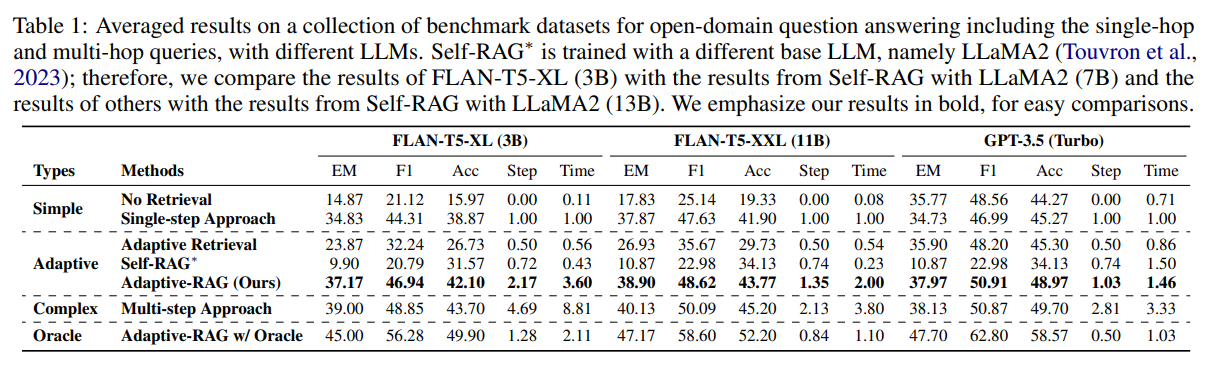

5. 결론
- 다양한 복잡도를 가지는 쿼리를 효과적이고 효율적으로 처리하기 위해 Adaptive-RAG를 제안
- Adaptive-RAG는 가장 간단한 쿼리는 Non Retrieval, 중간 복잡도는 Single-step, 복잡한 쿼리는 Multi-step QA로 처리
- Adaptive-RAG의 핵심은 쿼리의 복잡도를 잘 판단하는 것
- 다양한 쿼리 복잡도를 획일적으로 처리하는 기존 방식과 비교하여, QA 시스템의 전반적인 정확성과 효율성을 향상시킴
# Reference