-
[논문리뷰] ARAGOG: Advanced RAG Output Grading(2024)카테고리 없음 2024. 4. 30. 07:10
1. 도입
- RAG(검색 증강 생성)는 외부 지식을 LLM 출력에 반영하기 위해 많이 사용됨
- RAG의 활용과 연구가 늘고 있지만, 다양한 RAG 테크닉에 대한 실험 비교 연구는 없음
- 본 논문은 주요 Advanced RAG 테크닉을 검색 정확도와 답변 유사성으로 평가한 결과를 공개
- RAG 적용시 참고할만한 유용한 레퍼런스 정보를 제공
2. 도입
- RAG는 외부 지식 소스를 LLM에 통합하여, 환각 제거 및 정보를 반영한 출력 생성 능력을 향상시킴

- RAG의 활용과 연구가 늘고 있지만, Advanced RAG의 다양한 기법에 대한 실험 비교 연구는 없음
- 본 논문은 다양한 RAG 기법과 그 조합에 평가 정보를 제공하여 실제 적용 가능성에 대한 통찰력을 제공함
- Advanced RAG 기법 중 아래의 기법들에 대해 Naive RAG와 성능 비교평가를 실시3. Advanced RAG Techniques 소개
3.1 Sentence-window retrieval
- 작은 문장단위로 청킹 후 검색된 청크를 LLM에 제공시, 해당 청크의 주변 문장들도 함께 제공
- 검색된 문장 주위의 문장들도 추가함으로써 LLM이 답변 생성시 더 풍부한 컨텍스트 정보 활용이 가능
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo/출처: https://docs.llamaindex.ai/en/stable/optimizing/production_rag
3.2 Document summary index
- 문서의 요약과 청크들을 색인화하여 DB에 저장
- 문서 요약 내용을 바탕으로 쿼리와 관련된 문서 선택 후 해당 문서의 청크를 검색하여 답변 생성
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/index_structs/doc_summary/DocSummary/출처: https://medium.com/llamaindex-blog/a-new-document-summary-index-for-llm-powered-qa-systems-9a32ece2f9ec
3.3 HyDE
- LLM을 활용하여 쿼리에 대한 가상 답변을 생성. 생성한 가상 답변을 쿼리로 사용하여 관련 청크 검색
- 쿼리와 청크의 표현 차이로 인한 임베딩 검색 성능 저하를 개선
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/query_transformations/HyDEQueryTransformDemo/출처: https://medium.aiplanet.com/advanced-rag-improving-retrieval-using-hypothetical-document-embeddings-hyde-1421a8ec075a
3.4 Multi-query
- LLM을 활용하여 쿼리와 유사한 여러개의 유사 쿼리 생성
- 원본 쿼리 + 유사 쿼리를 바탕으로 청크 검색
- 필요시 원본 쿼리와 가장 관련이 높은 청크에 우선순위를 부여하는 Rerank 기법 적용
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/query_transformations/query_transform_cookbook/#query-rewriting-custom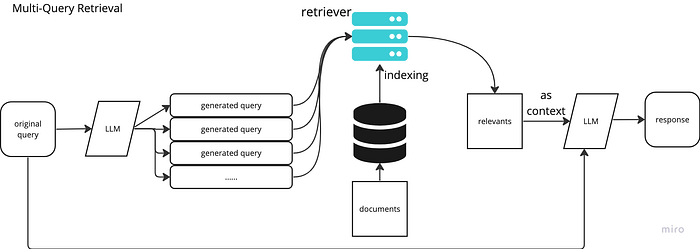
출처: https://teetracker.medium.com/langchain-llama-index-rag-with-multi-query-retrieval-4e7df1a62f83
3.5 Maximum Marginal Relevance
- 검색되는 청크의 중복성을 피하고 쿼리와 관련성 있는 다양한 청크를 LLM에 제공함
- 청크들간의 유사성과 다양성을 측정하는 MMR 점수 계산을 통해 중복되지 않는 다양한 청크를 선택
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/vector_stores/SimpleIndexDemoMMR/?h=maximum+marginal+relevance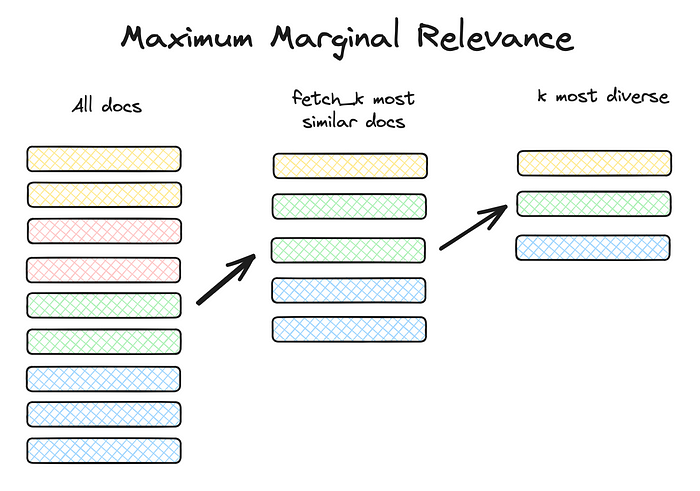
출처: https://towardsdatascience.com/rag-how-to-talk-to-your-data-eaf5469b83b0
3.6 Cohere Rerank
- 검색된 청크들과 쿼리와의 관련성을 크로스 인코더 방식으로 측정하여 청크의 우선 순위를 재 정렬
- 관련성 높은 청크를 우선하여 LLM에 제공하므로 답변 품질을 향상시킴
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/CohereRerank/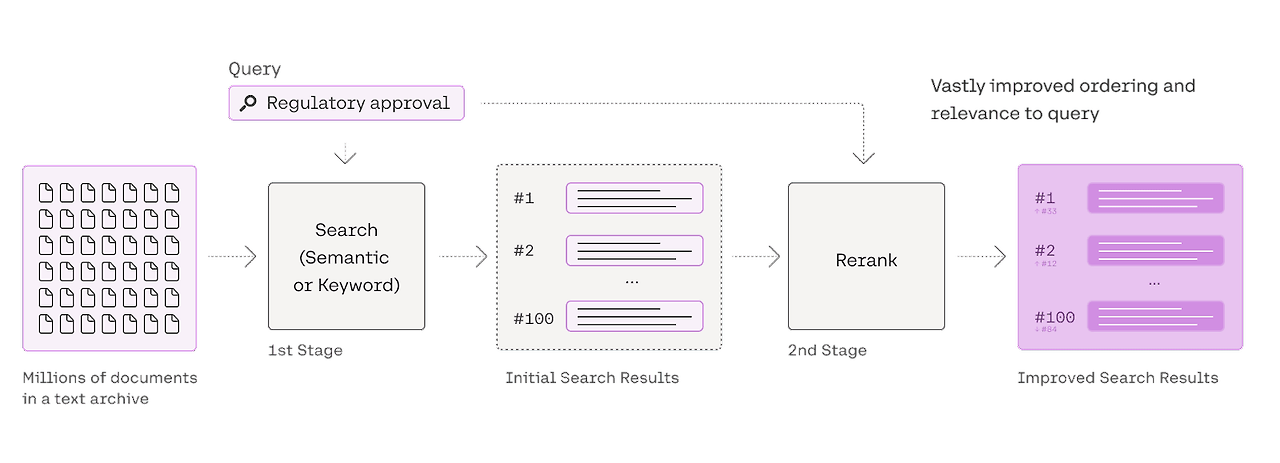
출처: https://cohere.com/blog/rerank
3.7 LLM rerank
- 검색된 청크의 우선순위 재정렬 작업에 LLM을 직접 적용
- 크로스 인코더 모델에 비해 처리 속도와 비용 효율은 떨어지나, 더 높은 정확도를 달성할 수 있음
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/LLMReranker-Gatsby/
4. 평가
4.1 데이터셋
- 인공지능과 LLM을 주제로 한 423개의 논문 선정
- 그중 13개의 논문에 대한 107개의 질문-답변 쌍 생성
- 질문-답변은 GPT-4를 사용하여 생성 후 사람이 검증
- 전체 423개 논문을 데이터 베이스로 하여 107개 질문에 대한 RAG 성능 평가
4.2 평가지표
- Retrieval Precision와 Answer Similarity로 RAG 테크닉들을 비교 평가(GPT-3.5 사용)
1) Retrieval Precision : 쿼리와 청크와의 관련성 정도. 0~1점 범위의 점수로 정량화
2) Answer Similarity : 생성된 답변이 실제 답변과 얼마나 잘 일치하는지를 0-5점 척도로 평가
4.3 평가결과
4.3.1 Retrieval Precision
- Sentence window retrieval이 가장 효과적
- LLM Rerank, HyDE도 Naive RAG보다 우수
- MMR과 Cohere Rerank는 Naive RAG보다 약간 나음
- Multi Query는 Naive RAG보다 안좋음
- Document summary index는 기존 Vector DB보다 우수
- 최고의 조합은 Sentence window retrieval + LLM Rerank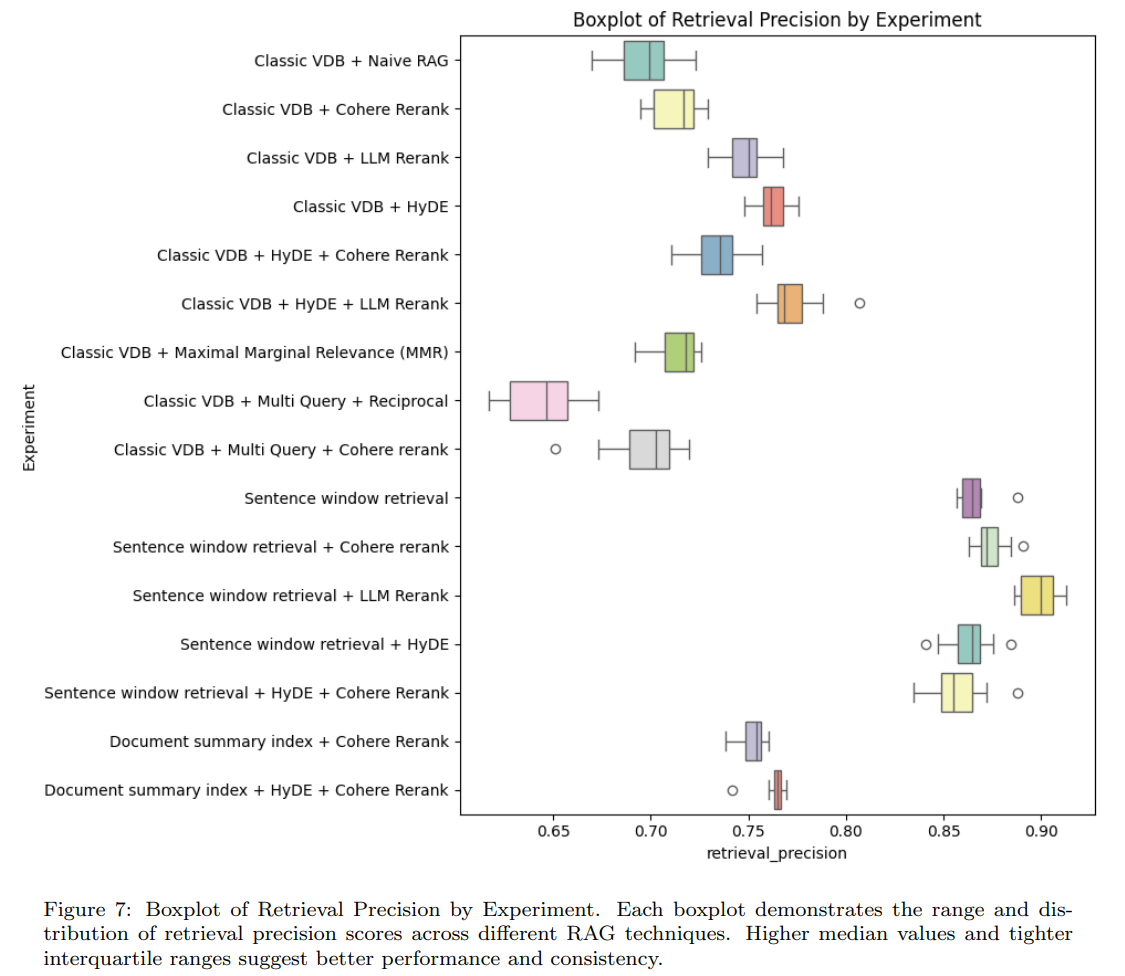
4.3.2 Answer Similarity
- Cohere/LLM Rerank, MMR은 Naive RAG보다 약간 나음
- HyDE는 Naive RAG보다 약간 떨어짐
- Multi Query는 Naive RAG보다 안좋음
- Document summary index는 기존 Vector DB보다 안좋음
- Sentence window retrieval은 가장 안좋음
- 최고의 조합은 Classic VDB + HyDE + Cohere Rerank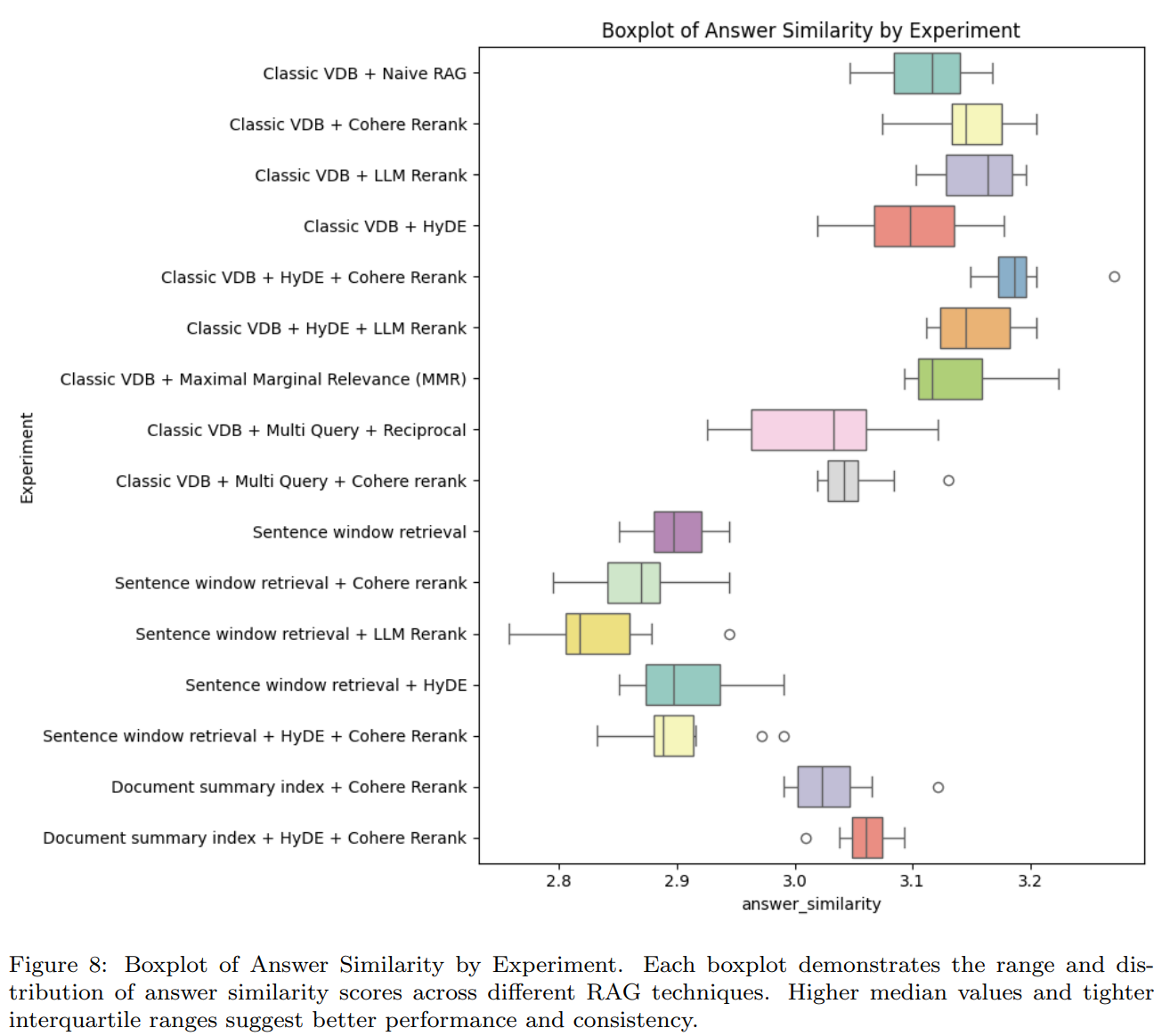
5. 결론
- HyDE와 LLM Rerank는 Retrieval Precision와 Answer Similarity 모두 좋은편
- MMR과 Cohere Rerank는 Naive RAG 대비 눈에 띄는 성과를 내지 못함
- Multi query는 두 지표 모두 성능이 낮음
- Sentence window retrieval은 Retrieval Precision은 가장 우수하지만, Answer Similarity는 최악임
- Document summary index는 Retrieval Precision에서만 조금 좋음
# 참고한 자료
https://arxiv.org/abs/2404.01037
ARAGOG: Advanced RAG Output Grading
Retrieval-Augmented Generation (RAG) is essential for integrating external knowledge into Large Language Model (LLM) outputs. While the literature on RAG is growing, it primarily focuses on systematic reviews and comparisons of new state-of-the-art (SoTA)
arxiv.org
https://github.com/predlico/ARAGOG
GitHub - predlico/ARAGOG: ARAGOG- Advanced RAG Output Grading. Exploring and comparing various Retrieval-Augmented Generation (R
ARAGOG- Advanced RAG Output Grading. Exploring and comparing various Retrieval-Augmented Generation (RAG) techniques on AI research papers dataset. Includes modular code for easy experimentation an...
github.com
