-
ARAGOG: Advanced RAG Output Grading(2024)카테고리 없음 2024. 4. 30. 07:39
1. Abstract
- Retrieval Augmented Generation (RAG) is widely used to incorporate external knowledge into LLM outputs
- Despite the growing use and research on RAG, there is no experimental comparison of different RAG techniques.
- This paper presents the results of evaluating major advanced RAG techniques in terms of retrieval precision and answer similarity.
- Provides useful reference information for applying RAG2. Introduction
- RAG integrates external knowledge sources into LLM, improving its ability to eliminate halucination and produce informed output
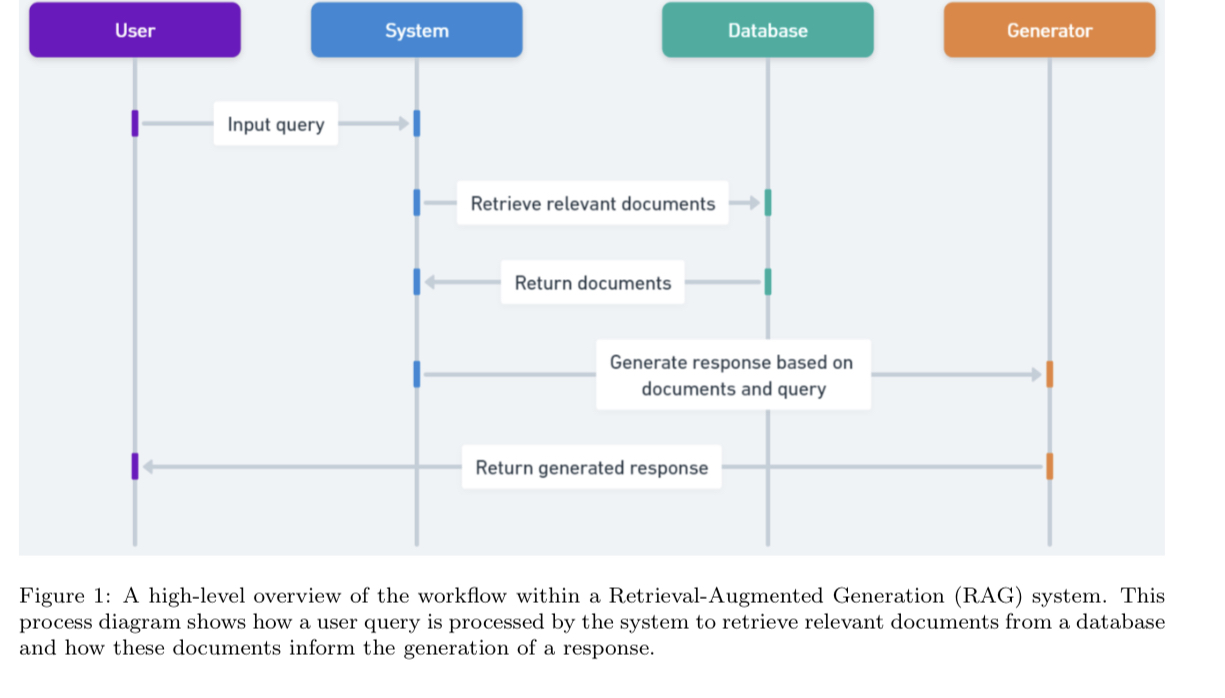
- While RAG is increasingly utilized and studied, there is no experimental comparison of various techniques in Advanced RAG.
- This paper provides evaluation information on various RAG techniques and their combinations to provide insight into their practical applicability.
- The following advanced RAG techniques are evaluated against naive RAG for performance
d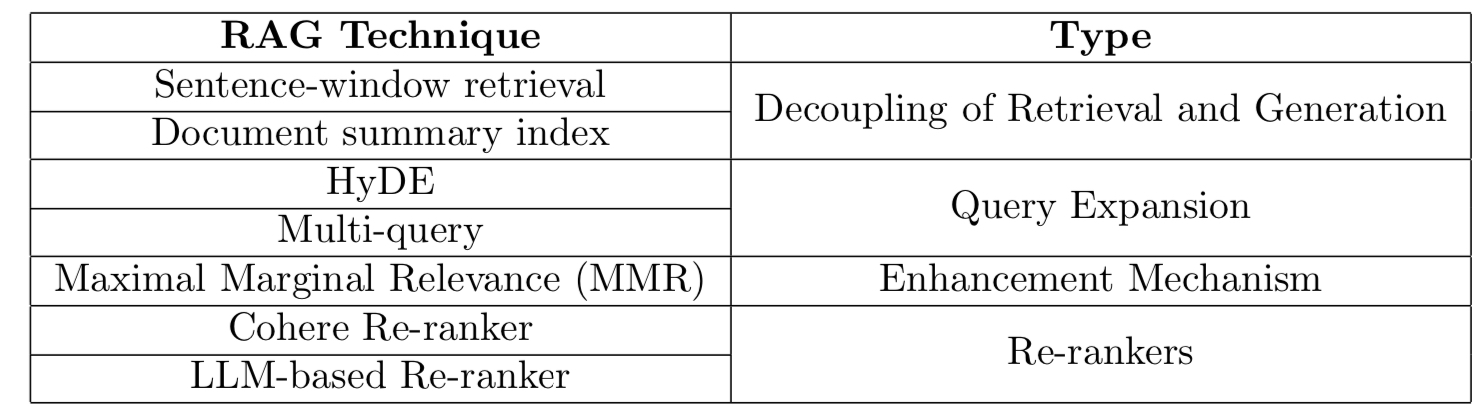
3. Advanced RAG Techniques
3.1 Sentence-window retrieval
- Chunking into smaller sentence chunks and providing LLM with the searched chunks along with the sentences surrounding them
- By adding the sentences surrounding the searched sentence, LLM can utilize richer contextual information when generating answers.
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo/
출처: https://docs.llamaindex.ai/en/stable/optimizing/production_rag
3.2 Document summary index
- Index and store document summaries and chunks in the DB
- Select documents related to the query based on the document summaries and retrieve chunks of those documents to generate answers
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/index_structs/doc_summary/DocSummary/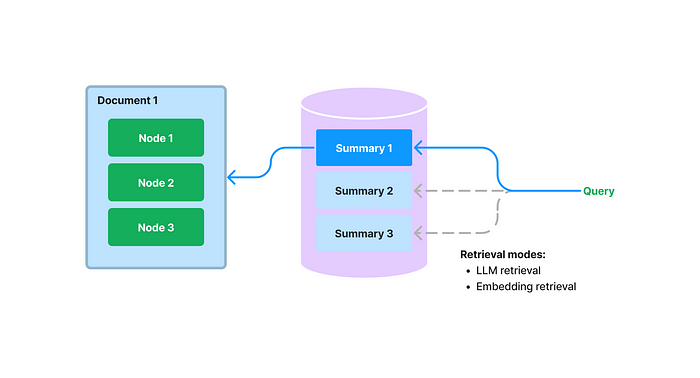
출처: https://medium.com/llamaindex-blog/a-new-document-summary-index-for-llm-powered-qa-systems-9a32ece2f9ec
3.3 HyDE
- Utilize LLM to generate a hypothetical answer to a query. Use the generated hypothetical answer as a query to retrieve related chunks.
- Improve embedding search performance due to differences in representation between query and chunk
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/query_transformations/HyDEQueryTransformDemo/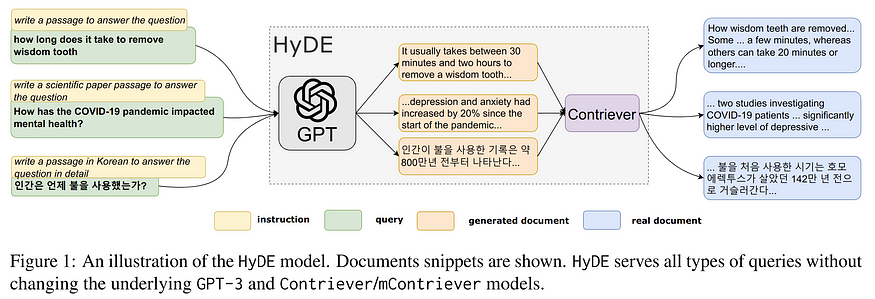
출처: https://medium.aiplanet.com/advanced-rag-improving-retrieval-using-hypothetical-document-embeddings-hyde-1421a8ec075a
3.4 Multi-query
- Utilizing LLM to generate multiple queries similar to a query
- Retrieve chunks based on the original query + similar queries
- Apply Rerank technique to prioritize chunks that are most relevant to the original query if needed
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/query_transformations/query_transform_cookbook/#query-rewriting-custom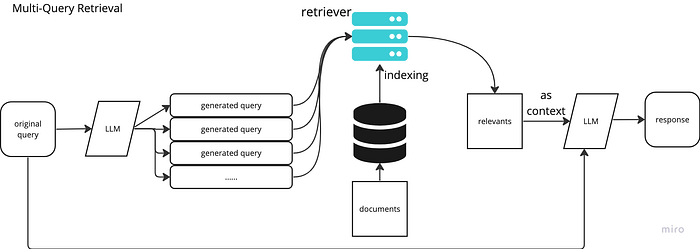
출처: https://teetracker.medium.com/langchain-llama-index-rag-with-multi-query-retrieval-4e7df1a62f83
3.5 Maximum Marginal Relevance
- Avoid redundancy in the chunks retrieved and provide LLM with a variety of chunks that are relevant to the query
- Calculate MMR score, which measures the similarity and diversity between chunks, to select a diverse set of non-duplicate chunks
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/vector_stores/SimpleIndexDemoMMR/?h=maximum+marginal+relevance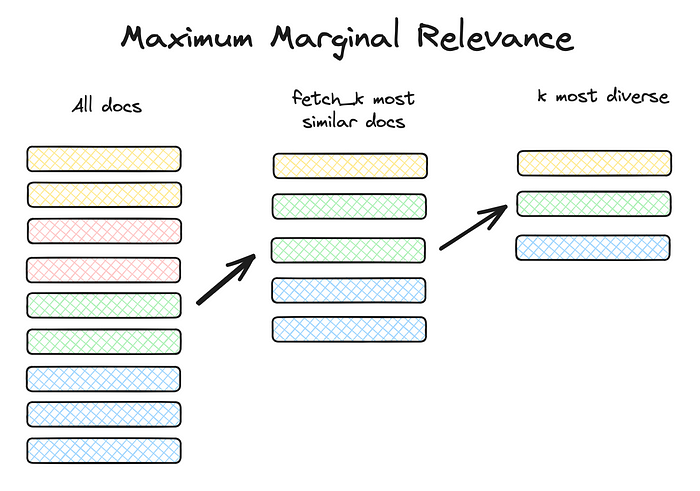
출처: https://towardsdatascience.com/rag-how-to-talk-to-your-data-eaf5469b83b0
3.6 Cohere Rerank
- Re-prioritizes chunks by cross-encoding retrieved chunks and measuring their relevance to the query
- Prioritizes the most relevant chunks and serves them to the LLM, improving the quality of answers
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/CohereRerank/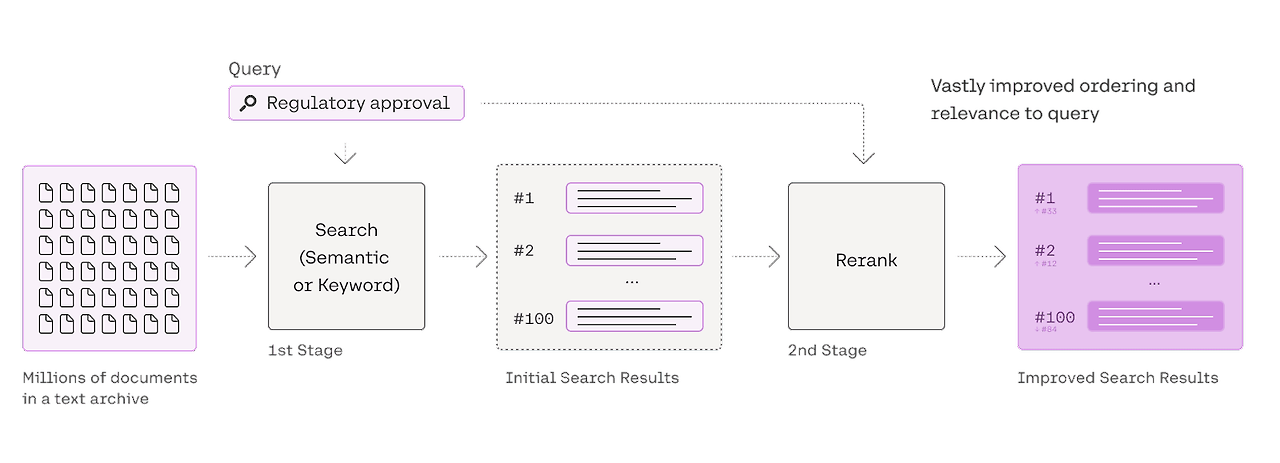
출처: https://cohere.com/blog/rerank
3.7 LLM rerank
- Apply LLM directly to priority reordering of retrieved chunks
- Less processing speed and cost-effective than the cross-encoder model, but can achieve higher accuracy
- LlamaIndex Code : https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/LLMReranker-Gatsby/
4. Evaluation
4.1 Dataset
- Selected 423 papers on the topic of AI and LLMs
- Generated 107 question-answer pairs for 13 of those papers
- Question-answers were generated using GPT-4 and then human-validated
- Evaluated RAG performance on 107 questions using all 423 papers as a database
4.2 Metrics
- Evaluating RAG techniques with Retrieval Precision and Answer Similarity (using GPT-3.5)
1) Retrieval Precision: The degree of relevance of a query to a chunk. Quantified by a score ranging from 0 to 1.
2) Answer Similarity: How well the generated answer matches the actual answer on a scale of 0-5.
4.3 Result
4.3.1 Retrieval Precision
- Sentence window retrieval is the most effective
- LLM Rerank and HyDE are also better than Naive RAG
- MMR and Cohere Rerank are slightly better than Naive RAG
- Multi Query is worse than Naive RAG
- Document summary index is better than the existing Vector DB
- The best combination is Sentence window retrieval + LLM Rerank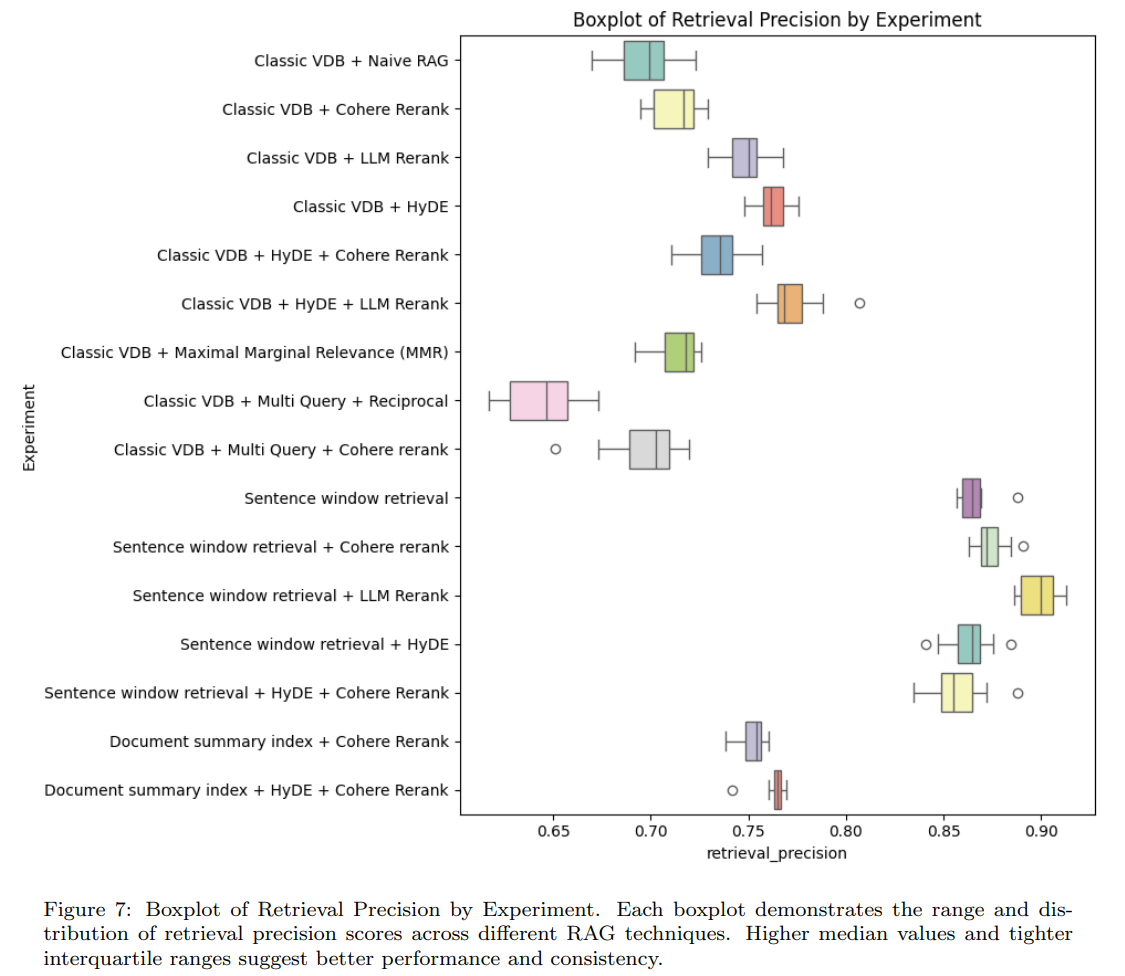
4.3.2 Answer Similarity
- Cohere/LLM Rerank, MMR is slightly better than Naive RAG
- HyDE is slightly worse than Naive RAG
- Multi Query is worse than Naive RAG
- Document summary index is worse than the existing Vector DB
- Sentence window retrieval is the worst
- Best combination is Classic VDB + HyDE + LLM Rerank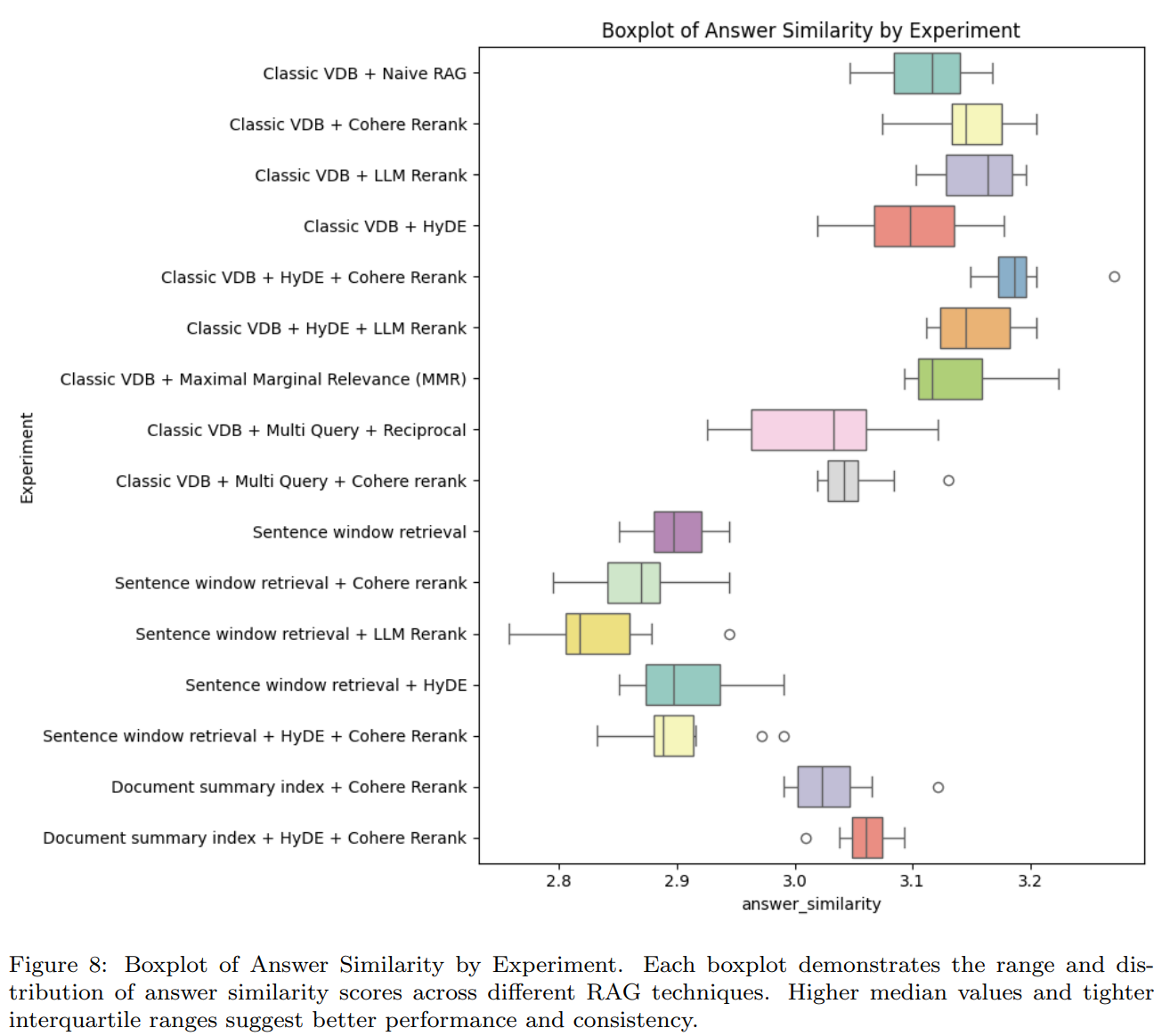
5. Conclusion
- HyDE and LLM Rerank are good for both Retrieval Precision and Answer Similarity
- MMR and Cohere Rerank do not perform significantly better than Naive RAG
- Multi query performs poorly on both metrics
- Sentence window retrieval has the best Retrieval Precision but the worst Answer Similarity
- Document summary index is only slightly better on Retrieval Precision
6. References
https://arxiv.org/abs/2404.01037
ARAGOG: Advanced RAG Output Grading
Retrieval-Augmented Generation (RAG) is essential for integrating external knowledge into Large Language Model (LLM) outputs. While the literature on RAG is growing, it primarily focuses on systematic reviews and comparisons of new state-of-the-art (SoTA)
arxiv.org
https://github.com/predlico/ARAGOG
GitHub - predlico/ARAGOG: ARAGOG- Advanced RAG Output Grading. Exploring and comparing various Retrieval-Augmented Generation (R
ARAGOG- Advanced RAG Output Grading. Exploring and comparing various Retrieval-Augmented Generation (RAG) techniques on AI research papers dataset. Includes modular code for easy experimentation an...
github.com