-
[논문리뷰] ARES: An Automated Evaluation Framework for RAG System(2024)카테고리 없음 2024. 5. 9. 11:54
1. Abstract
- RAG 시스템에 대한 평가는 전통적으로 입력 쿼리, 검색할 구절, 생성할 답변에 대한 수작업 주석이 필요
- 본 본문에서는 RAG 시스템을 평가할 수 있는 자동화된 RAG 평가 시스템 ARES를 소개
- ARES는 스스로 합성 학습 데이터를 생성하고, 경량의 평가모델을 Fine-tuning하여 RAG 구성 요소의 품질을 평가
- ARES는 사람이 주석을 단 작은 데이터 포인트만을 필요로 함
- ARES는 도메인 이동과 적용에도 효과적
2. Introduction
- RAG 시스템은 Retriever가 질문과 관련된 구절을 찾고 LM이 이 구절을 사용하여 응답을 생성함
- 이 프로세스는 Retriever 선택, Chunking 방법, LM의 Fine-tuning 여부 등 다양한 선택지를 포함함
- Data의 크기와 유형, 도메인 및 예산 등에 따라 최적의 RAG 시스템은 매번 달라짐
- RAG 시스템의 평가 및 최적화를 위해서는 쿼리, 답변, 검색된 Chunk에 대한 많은 레이블 작업이 필요
- 본 논문에서는 RAG 시스템을 신속하고 정확하게 평가하기 위해 자동화된 RAG 평가 시스템인 ARES를 제안
- ARES는 RAG 파이프라인의 각 구성 요소에 대해 맞춤형 평가모델을 생성하는 방법
- ARES는 세가지 지표로 RAG 시스템을 평가
1) Context relevance(문맥 관련성) : 검색된 정보가 쿼리와 관련이 있는지
2) Answer faithfulness(답변 충실성) : 언어 모델이 생성한 답변이 검색된 문맥에 적절히 근거를 두고 있는지
3) Answer relevance(답변 관련성) : 답변이 질문과도 관련이 있는지
- ARES는 ①In-domain Chunk 샘플, ②150개 이상의 선호도 검증 세트, ③5개 이상의 질문-답변 샘플만 필요하므로 평가에 필요한 레이블 작업을 최소화 할 수 있음
3. ARES
3.1 Overview
1) 합성 데이터셋 생성 : LLM을 사용하여 In-domain Chunk 샘플에서 합성 질문 및 답변을 생성(FLAN-T5 XXL 사용)
2) 평가모델 훈련 : 질문-Chunk-답변 데이터를 사용하여 LLM기반 평가모델을 훈련(DeBERTa-v3-Large 사용)
3) 훈련된 평가 모델을 RAG 시스템 평가에 적용 : 질문-Chunk-답변 샘플에 점수를 매기고, 인간 선호도 검증 세트와 함께 예측 기반 추론을 사용하여 RAG 시스템 품질에 대한 신뢰구간을 추정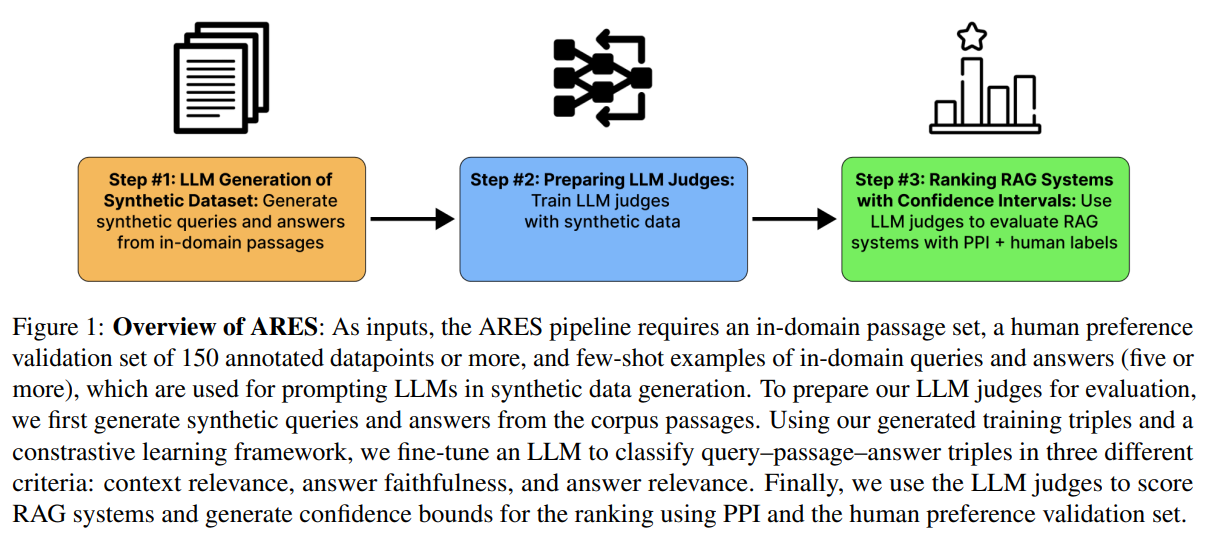
3.2 LLM Generation of Synthetic Dataset
- LLM을 사용해 In-domain Chunk 샘플에서 합성 질문과 답변을 생성(FLAN-T5 XXL 사용)
- 질문 답변 생성시 사전에 작성한 5개 이상의 질문-답변 샘플을 Few-shot learning으로 참조
- 생성된 데이터는 질문-Chunk-답변(예: 관련 있는 Chunk/관련 없는 Chunk, 정답/오답)의 긍정 및 부정 예시를 모두 포함
- Negative Sample은 두가지 방법으로 생성
1) 약한 Nagative : 질문과 전혀 관련이 없는 Chunk 샘플링, 다른 Chunk에서 생성된 답변 샘플링
2) 강한 Nagative : 동일 문서내 다른 Chunk 샘플링, 동일 Chunk에서 모순된 답변 생성 유도

합성 데이터 생성 방법 3.2 Preparing LLM Judges
- 합성 데이터 세트를 사용하여 DeBERTa-v3-Large을 Fine-tuning하여 평가모델 생성
- 평가 모델은 아래 세가지 지표를 잘 측정하도록 훈련
1) Context relevance(문맥 관련성) : 검색된 정보가 쿼리와 관련이 있는지
2) Answer faithfulness(답변 충실성) : 언어 모델이 생성한 답변이 검색된 문맥에 적절히 근거를 두고 있는지
3) Answer relevance(답변 관련성) : 답변이 질문과도 관련이 있는지
- 훈련시 150개 이상의 선호도 검증 세트를 사용
3.3 Ranking RAG Systems with Confidence Intervals
- ARES는 각 RAG 접근 방식에서 생성된 질문-Chunk-답변을 샘플링하고, 평가모델은 샘플링 데이터에 대해 문맥 관련성, 답변 충실도, 답변 관련성을 True/False로 예측
- 예측된 레이블의 평균을 구하여 세 가지 지표에 대한 RAG 시스템 성능을 평가
- ARES는 평가의 정확성을 높이기 위해 ARES는 예측 기반 추론(PPI) 사용
- PPI는 레이블이 지정된 데이터 포인트와 주석이 없는 데이터 포인트에 대한 평가결과를 모두 활용하여 RAG 시스템 성능에 대한 신뢰 구간을 구성
- 이를 위해 PPI는 인간 선호도 검증 세트의 LLM 판정자를 사용하여 주석이 없는 더 큰 데이터 세트에서 각 ML 예측을 사용하여 ML 모델 성능의 신뢰도 집합을 구성하기 위한 정류기 함수를 학습
- 신뢰도 집합을 사용하여 평가된 RAG 시스템의 성능에 대한 보다 엄격한 신뢰 구간을 생성
- 신뢰 구간의 중간점을 사용하여 RAG 시스템의 순위를 매김4. Evaluation
- ARES와 RAGAS, Gpt-3.5-turbo-16k(In-context Few-shot Learning)를 비교하여 RAG 시스템 평가 성능을 검증
4.1 데이터셋
- KILT 벤치마크 : Natural Questions (NQ), HotpotQA, FEVER, and Wizards of Wikipedia (WoW)
- SuperGLUE 벤치마크 : MultiRC와 ReCoRD
4.2 검증 결과
- RAGAS, GPT3.5 대비 평균적으로 더 정확한 RAG 시스템 평가 성능을 보임
4. Conclusion
- RAG를 위한 자동화된 평가 프레임워크인 ARES를 소개
- ARES는 합성적으로 생성된 쿼리와 답변에 대해 경량 LLM 판단자를 Fine-tuning할 수 있는 훈련 파이프라인을 제공
- ARES는 최소한의 인간 주석만을 필요로 하며, RAG 시스템의 각 구성 요소를 개별적으로 평가
- 기존의 자동 평가 프레임워크(RAGAS) 대비 RAG 시스템의 평가 성능이 우수
# 참고한 자료
https://arxiv.org/abs/2311.09476
ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
Evaluating retrieval-augmented generation (RAG) systems traditionally relies on hand annotations for input queries, passages to retrieve, and responses to generate. We introduce ARES, an Automated RAG Evaluation System, for evaluating RAG systems along the
arxiv.org
https://github.com/stanford-futuredata/ARES
GitHub - stanford-futuredata/ARES
Contribute to stanford-futuredata/ARES development by creating an account on GitHub.
github.com