-
[논문리뷰] FIT-RAG: Black-Box RAG with Factual Information and Token Reduction(2024)카테고리 없음 2024. 5. 23. 23:12
1. Abstract
- LLM을 블랙박스로 취급(LLM의 파라미터를 동결)하는 검색 증강 생성(RAG) 시스템은 많은 주목을 받고 있음
- 블랙박스 RAG 방식은 검색된 모든 문서를 LLM에 입력으로 연결하는데, 두 가지 문제가 있음
1) 답변 생성에 도움이 되지 않는 정보가 포함되어 있지 않을 수 있음
2) 단순히 검색된 모든 문서를 연결하면 LLM에 불필요한 토큰이 대량으로 입력되어 낭비가 발생
- 본 논문에서는 검색에서 사실 정보를 활용하고 증강 컨텍스트의 토큰 수를 줄이는 FIT-RAG를 제안
- FIT-RAG는 사실 정보와 LLM의 선호도를 각각 레이블로 사용하는 이중 레이블 문서 스코어를 구성하여 사실 정보를 활용
- Self-knowledge recognizer와 Sub-document-level token reducer를 도입하여 불필요한 증강 컨텍스트를 줄임
- 세 가지 오픈 도메인 질문-답변 데이터 세트(TriviaQA, NQ 및 PopQA)에 대해 탁월한 효과를 입증하며 토큰을 절반으로 줄임
2. Introduction
- LLM을 Fine-tuning하는 것은 비용효율이 나쁨
- LLM을 블랙박스로 취급(LLM의 파라미터를 동결)하는 검색 증강 생성(RAG) 시스템이 많은 주목을 받고 있음
- 기존 블랙박스 RAG 방식은 일반적으로 LLM의 선호도(예: 검색된 문서로 정답을 제공할 수 있는지 여부)에만 기반하여 Retriever를 Fine-tuning하고 검색된 모든 문서를 입력으로 연결하므로 효과와 효율성 모두 문제 있음
- 검색 시 LLM의 선호도만 고려할 경우, 사실 정보에 대한 무지가 발생하여 RAG의 효율성이 저하될 수 있음
- 그림 1에서 LLM은 검색된 문서로 정확한 답변이 가능하지만 검색된 문서에는 질문과 과련된 사실 정보가 없음
- 이러한 불필요한 문서가 Retriever에게 보상을 제공하는 데 사용되면 Retriever 를 오도할 수 있음
- 또한, 검색된 모든 문서를 입력으로 연결하면 토큰사용의 낭비가 발생함

- 사실 정보의 무지와 토큰 낭비를 피하기 위해, 사실 정보와 LLM 선호도를 모두 활용하고 입력 토큰에 대해 토큰 감소를 수행하는 FIT-RAG를 제안
- FIT-RAG는 ①Similarity based Retriever, ②Bi-label Document Scorer, ③Self-Knowledge Recognizer, ④Sub-document-level Token Reducer, ⑤Prompt Construction Module로 구성
- Bi-label Document Scorer는 사실 정보뿐만 아니라 LLM 선호도와의 정렬을 효과적으로 모델링하여 사실 정보의 무지를 방지
- Self-Knowledge Recognizer, Sub-document-level Token Reducer는 입력 토큰을 줄여 토큰의 낭비를 방지

- Bi-label Document Scorer는 ①사실 정보 라벨(Has_Answer)과 ②LLM 선호도 라벨(LLM_Prefer)의 이중 라벨로 학습
①사실 정보 라벨 : 문서에 질문에 대한 답변이 포함되어 있는지 여부
②LLM 선호도 라벨 : 문서가 LLM이 정확한 답변을 생성하는 데 도움이 되는지 여부
- Self-Knowledge Recognizer는 LLM이 질문과 관련된 지식을 이미 포함하고 있는지 추정하여 외부 지식 필요 여부를 결정 => 불필요한 컨텍스트 증강을 피함으로써 입력 토큰을 줄임.
- Sub-document-level Token Reducer는 검색된 문서에서 정답에 관련있는 Sub-document 조합만 선택 => 불필요한 하위 문서를 제거하여 입력 토큰을 줄임
3. FIT-RAG
- FIT-RAG는 다섯 가지 요소로 구성
①Similarity based Retriever : 코퍼스에서 질문과 관련된 문서를 검색
②Bi-label Document Scorer : 사실 정보와 LLM 선호도에 따라 검색된 문서에 점수를 매김
③Self-Knowledge Recognizer : 주어진 질문에 대해 외부지식 필요 여부를 판단
④Sub-document-level Token Reducer : 선별된 후보 문서에서 하위 문서를 추출하여 압축
⑤Prompt Construction Module : 답변 출력을 위해 질문, 하위문서, 지시문으로 프롬프트 구성
3.1 Bi-label Document Scorer
- 검색된 문서에 대한 사실 정보와 LLM의 선호도를 모두 평가하기 위해, 이중 라벨 학습을 적용하여 Bi-label Document Scorer 모델을 학습(T5 모델 LoRA Fine-tuining)
①사실 정보 라벨 : 문서에 질문에 대한 답변이 포함되어 있는지 여부
②LLM 선호도 라벨 : 문서가 LLM이 정확한 답변을 생성하는 데 도움이 되는지 여부
- 이중 라벨 학습 : 데이터 라벨 불균형 문제를 해결하기 데이터마다 다른 가중치를 부여하고 hypergradient-descent을 통해 가중치를 자동으로 학습

3.2 Self-Knowledge Recognizer
- 질문에 대해 LLM이 관련 지식을 가지고 있는지, 즉 외부 문서를 검색하지 않고도 답할 수 있는지를 판단하여 검색 필요 여부를 결정
- LLM은 Blackbox 모델이기 때문에 어떤 지식을 사전학습 했는지 파악할 수 없음
- LLM의 지식 보유 여부(검색 필요 여부)를 판단하기 위해 2가지의 방법을 적용
1) 위키피디아 페이지 조회수 활용
- 정보의 대중적 인기도와 언어 모델의 지식 기억 능력이 높은 상관관계가 있다는 기존 연구 결과 적용(When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories, 2023)
- 어떤 정보와 관련된 위키피디아 페이지의 조회수가 높을수록 LLM이 해당 지식을 잘 알고 있고, 조회수가 낮으면 잘 모른다는 원리
- 질문과 관계된 위키피디아 정보의 페이지 조회수가 임계치 이상이면 LLM이 해당 지식을 이미 알고있다고 판단
2) Labeld dataset의 KNN 적용
- LLM이 정보 없이 답을 할 수 있는지에 대한 labeled dataset을 구축
- 질문과 유사도가 높은 k개 datapoint를 찾고 검색필요 여부 라벨값의 Voting으로 검색필요 여부 결정

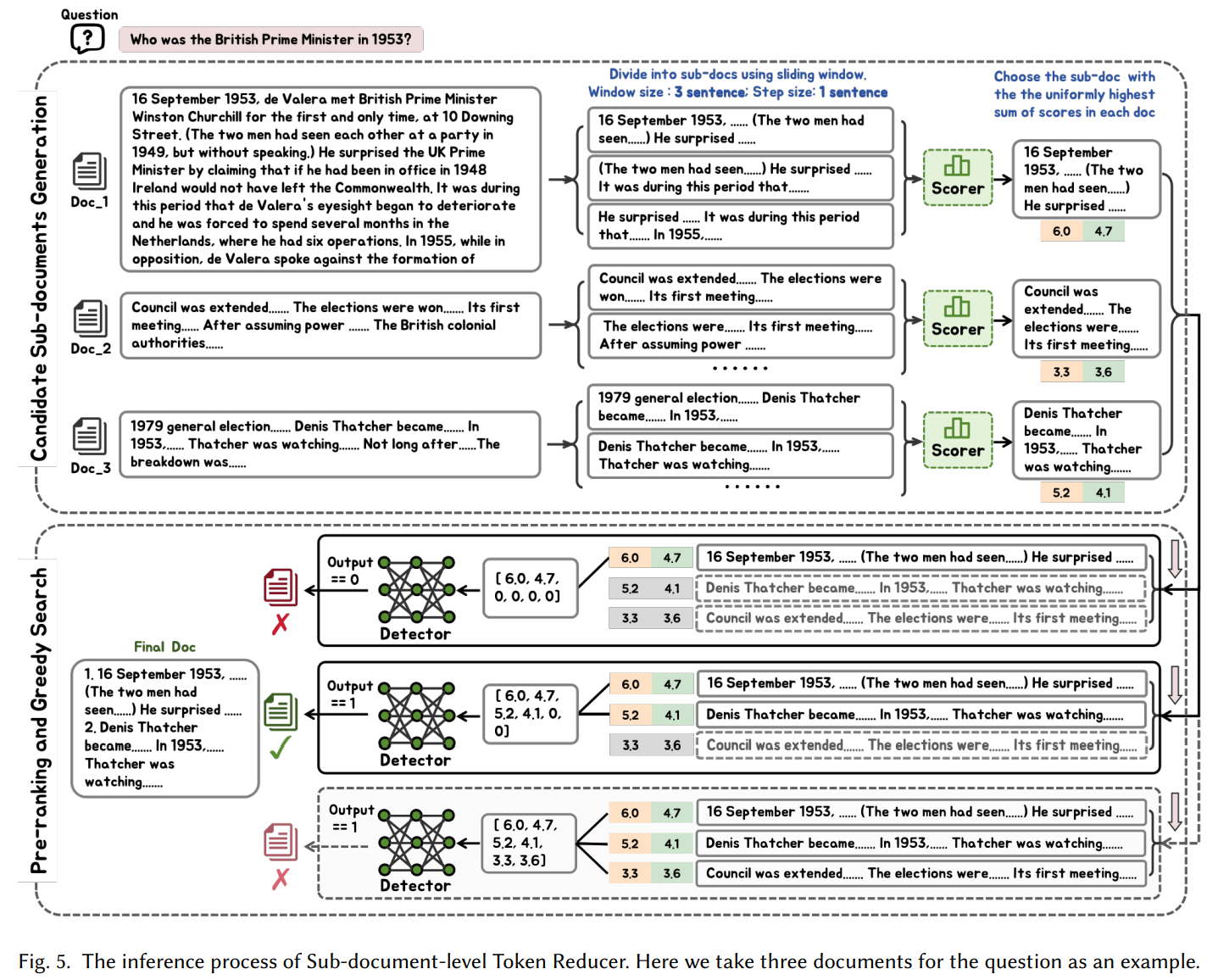
3.3 Sub-document-level Token Reducer
- 먼저 Bi-criteria Reranker로 검색된 후보 문서의 순위를 재조정하고 상위 10개 문서를 선택
- Sub-document-level Token Reducer로 불필요한 토큰을 추가로 제거. 실험결과 토큰을 절반으로 줄임
3.3.1 Bi-criteria Reranker- 리트리버가 검색한 100개의 문서의 순위를 재조정하여 상위 10개 문서를 선택
- 순위 재조정은 Bi-label Document Scorer의 사실 정보 점수 & LLM 선호도 점수의 합산 순서로 조정
- 답변 생성에 도움되지 않는 불필요한 Context Token 제거
3.3.2 Sub-document-level Token Reducer
- 검색된 문서에는 일반적으로 질문과 관련이 없는 콘텐츠도 포함되어 있음
- Sub-document-level Token Reducer는 검색된 문서를 하위 문서로 분할하고 질문과 관련 있는 소량의 하위 문서만을 선택
- Sub-document-level Token Reducer는 다음과 같이 구성
①Sub-document Generator : 문서를 세문장 단위의 작은 문서로 분할
②Eligible Augmentation Detector : 하위 문서 조합이 답변 생성에 도움이 되는지 판단(Llama2-13B Fine-tuning 모델 사용)
③Sub-document Filter : 적절한 하위 문서 조합 선택
3.4 Prompt Construction
- 지시문, 검색된 문서, 질문을 프롬프트로 구성하여 답변 유도
- 지시문은 다음 3개 문장으로 구성하여 답변 성능을 향상시킴
1) LLM에게 다음 구절을 참조하여 질문에 답하도록 요청
2) 질문을 주의 깊게 읽고 이해해야 한다는 점을 강조
3) 질문에 답하고 왜 이 답을 선택했는지 설명 요청
- No_Retrieve의 경우, 질문에 대한 배경 구절을 생성후 답변하도록 지시


4. Evaluation
4.1 데이터셋
- 오픈 도메인 질문 답변 데이터셋인 TriviaQA, NQ, PopQA
4.2 검증 결과
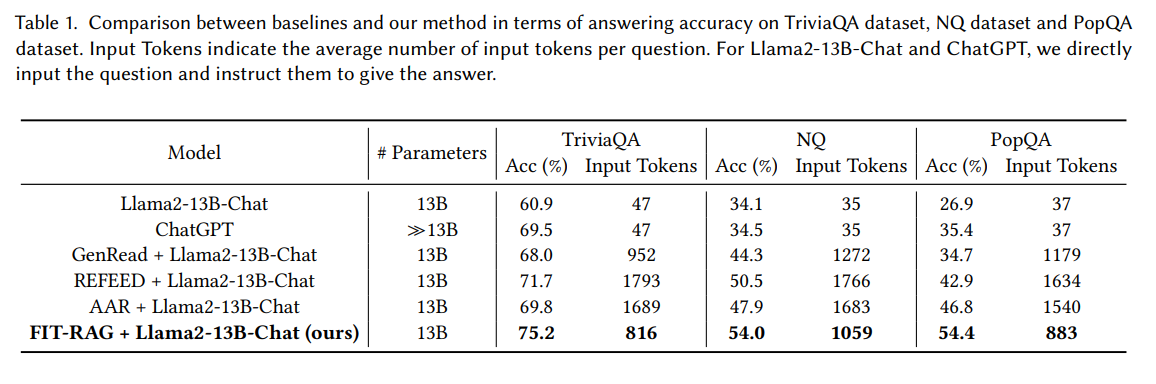
- Llama2-13B without RAG 대비 TriviaQA 데이터 세트에서 14.3%, NQ 데이터 세트에서 19.9%, PopQA 데이터 세트에서 27.5%의 답변 정확도를 향상- 다른 RAG 프레임워크 대비 우수한 성능 + 절반의 토큰만 사용 => 토큰 효율성과 계산 리소스를 절약
5. Conclusion
- 뛰어난 효과와 토큰 효율성을 모두 달성하는 RAG 프레임워크인 FIT-RAG를 제안
- FIT-RAG는 사실 정보와 LLM 선호도를 모두 검색에 활용함으로써 블랙박스 RAG의 효율성을 향상
- 자체 지식을 충분히 활용하고 하위 문서 수준의 토큰 감소를 수행함으로써 토큰 효율을 향상
# 참고한 자료