-
[논문리뷰] Similarity is Not All You Need: Endowing Retrieval-Augmented Generation with Multi–layered Thoughts(2024)카테고리 없음 2024. 6. 6. 22:59
1. Abstract
- 기존의 RAG는 일반적으로 유사성을 쿼리와 관련 문서의 매칭 방법으로 사용
- 이 연구에서는 유사성이 '만병통치약'이 아니며 유사성에 의존하면 검색 증강 생성의 성능이 저하됨을 강조
- 이를 개선하기 위해 Multi-layered Thoughts를 적용하는 MetRag를 제안
- 기존의 유사성 기반 사고(similarity-oriented thought)를 넘어서, LLM의 지도를 통해 효용성 기반 사고(utility-oriented thought)를 활용하는 소규모 효용 모델(small-scale utility model)을 훈련
- 유사성 기반 사고와 효용성 기반 사고를 종합적으로 결합하여 Chunk 선택에 적용
- 검색된 문서집합을 효율적으로 요약하기 위해 작업 적응형 요약기(task-adaptive summarizer)를 훈련시키고 간결성 기반 사고(compactness-oriented thought)를 적용
- Multi-layered Thoughts(similarity-oriented thought, utility-oriented thought, compactness-oriented thought)를 통해 RAG의 의 품질을 개선
2. Introduction
- 기존의 RAG는 일반적으로 유사도에 따라 외부 지식 문서를 검색
- 이 연구에서는 유사성이 검색 증강 생성의 '만병통치약'은 아니며 유사성에 의존하면 성능이 저하될 수 있음을 강조(그림 1)
- 또한 LLM의 컨텍스트 제한으로 인해 단순히 상위 k개를 집계하여 다수의 검색된 문서를 활용하는 방식은 컨텍스트 양을 과도하게 증가시켜 LLM에게 혼동을 줌
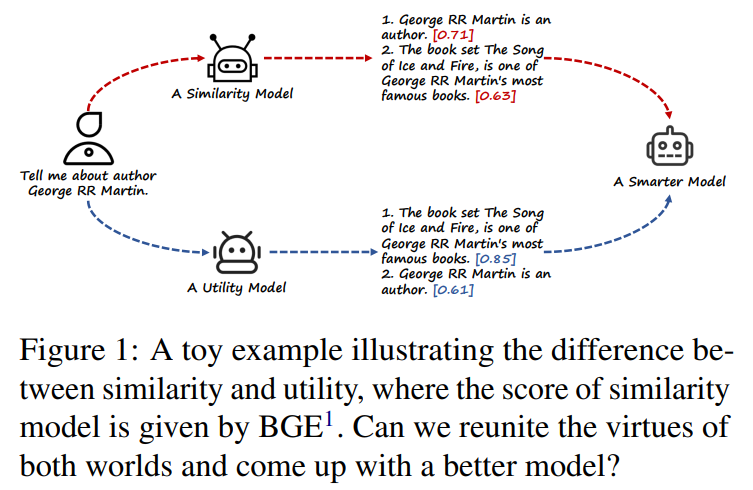
- 상기의 한계를 극복하기 위해서는 유사성 외에도 다양한 Multi-layered Thoughts(utility- and compactness-oriented thought)를 RAG에 적용하는것이 필요
- 이를 위해서는 아래 선결 과제의 해결이 필요
① Utility-oriented thought : 효용 지향적 사고를 인식할 수 있는 모델이 필요하며, 훈련을 위해 라벨이 지정된 데이터가 필요② Compactness-oriented thought : 수십 개의 문서가 LLM에 주는 부담을 줄이기 위해 단순 문서 요약이 아닌 중요 정보를 포함하여 요약하는 요약 모델의 훈련이 필요
[Solution for ①]
- MetRAG는 LLM(gpt-4 등)을 활용하여 입력 쿼리에 대한 문서의 유용성(utility)을 감독하고, LLM의 피드백을 label로 하여 sLLM으로 유용성 모델을 훈련
- Similarity-oriented thought와 Utility-oriented thought를 결합하기 위해 Simililarity 모델과 Utility 모델의 출력을 모두 고려
[Solution for ②]
- Compactness-oriented thought 부여를 위해, LLM Teacher 모델(예: GPT4)로 부터 sLLM 기반 모델의 요약 능력을 증류(distill)
- 이후 여러 개의 생성된 요약과 Reward model을 사용하여 요약 모델이 Task에 맞춰지도록 추가로 제약
- 이전 단계에서 Multi-layered Thoughts 기반으로 추출된 Chunk를 지식 증강 생성(knowledge-augmented generation)에 적용
3. MetRAG
- MetRag(그림2)는 크게 3단계로 구성
1) Simliarity Model과 Utility Model을 결합하여 검색된 문서의 유사성과 효용성을 종합하여 판단
2) Task-Adaptive Summarizer를 통해 Task에 필요한 정보를 보존하며 문서 정보를 압축
3) Multi-layered Thoughts를 통해 추출된 Chunk를 SFT LLM에 입력하여 최종 답변을 생성
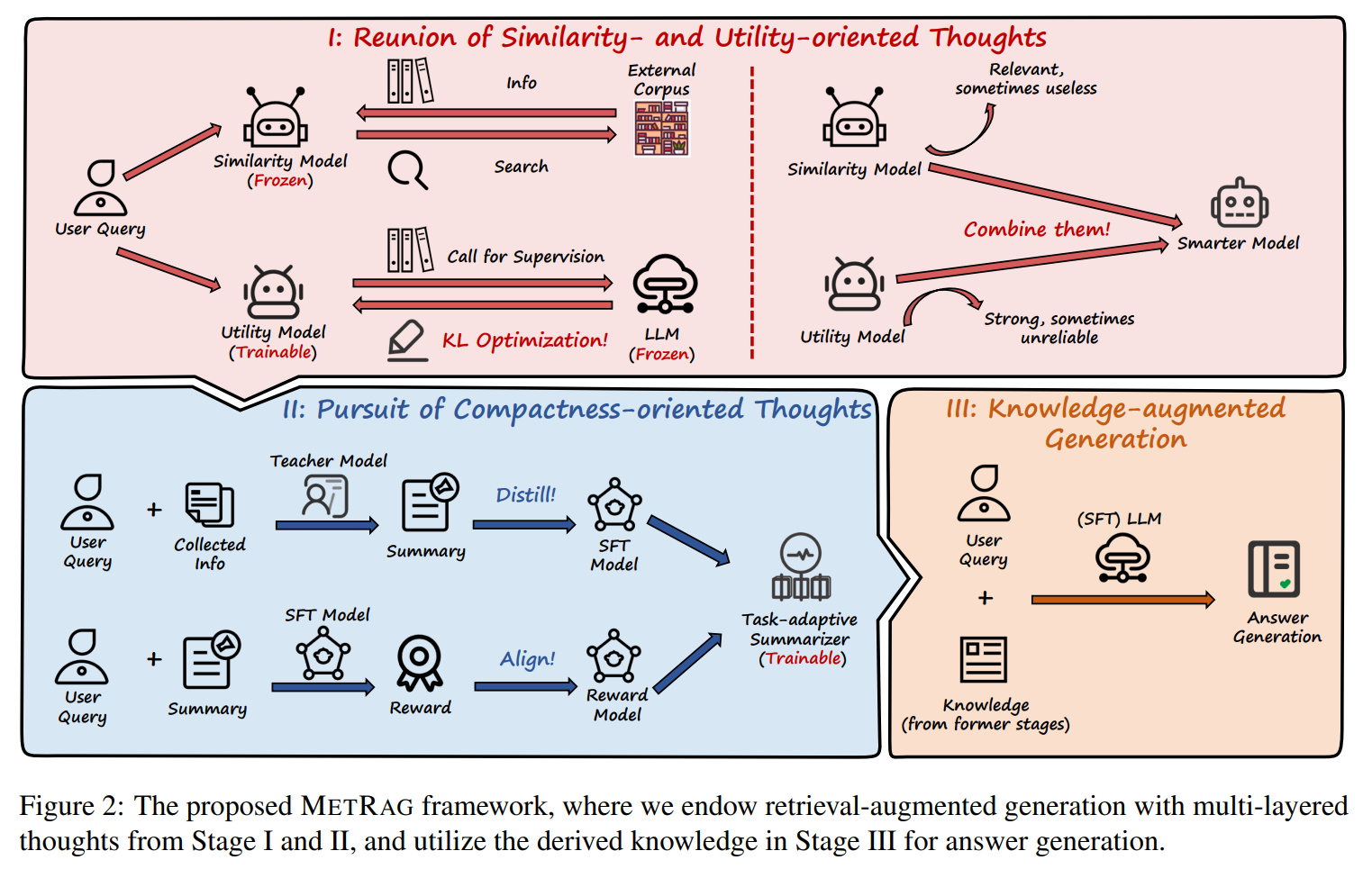
3.1 Similarity Model & Utility Model
- Similarity Model : Embedding Vector의 Cosine Similarity 기반으로 입력 쿼리와 유사성 높은 문서를 효율적으로 검색
- Utility Model : 문서가 답변생성에 도움이 되는지(답변에 필요한 정보를 포함 여부 등)에 대해 판단(sLLM supervied by LLM)
- 두 모델의 결과를 결합 -> Similarity Score 또는 Utility Score가 임계값 이상인 경우만 Chunk로 선택
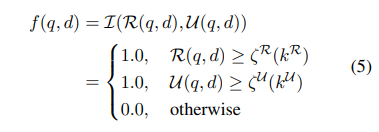
Similarity Model & Utility Model 결합 방법 3.2 Compactness-oriented Thoughts Model (Task-adaptive Summarizer)
- LLM의 컨텍스트 제한으로 인해 단순히 Top-𝑘 문서를 집계하면 정보 손실과 성능 저하가 발생할 수 있음
- 그러나 검색된 문서의 단순 요약은 입력 쿼리와 관련된 중요한 정보가 생략될 수 있음
- 따라서 중요한 정보를 유지하며 검색된 문서들의 내용을 요약하도록 Task에 Align된 요약 모델을 학습시켜야 함
- 작업 적응형 요약기(Task-adaptive Summarizer)를 통해 LLM의 답변 성능을 향상시키고 계산 비용을 절감함
- Task-adaptive Summarizer는 LLM(GPT-4 등)의 Teacher 모델을 통해 요약 능력을 훈련(Distill)시키고 Lora 튜닝을 통해 Task align된 요약 모델(Supervied Fintuning Model)을 생성
- 이후 SFT 요약모델의 보상 훈련을 통해 Task와 관련된 정보를 더 잘 포착하며 요약하도록 훈련
3.3 Knowledge-augmented Generation
- 질문-답변 데이터셋으로 Fine-tuning된 SFT 모델을 통해 입력 쿼리와 이전 단계에서 생성된 Chunk를 활용하여 답변을 생성
4. Evaluation
4.1 데이터셋
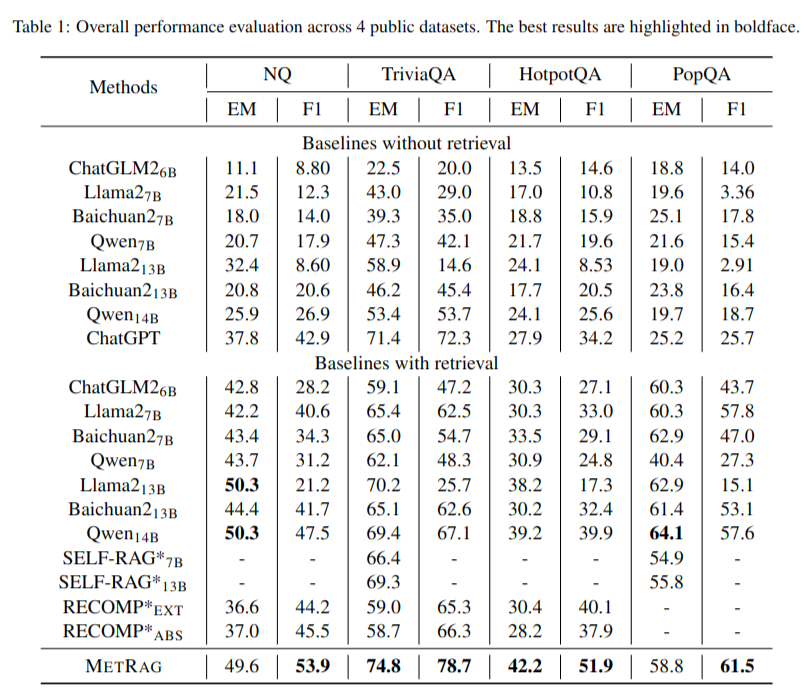
- 오픈 도메인 QA를 포함한 다양한 데이터셋에 테스트 NQ, TriviaQA-unfiltered2, HotpotQA 등4.2 결과
- LLM without RAG 또는 다른 RAG 모델 대비 대부분의 벤치마크에서 가장 좋은 성능 달성- MetRag은 다층적 사고를 통해 검색된 문단의 가장 유용한 정보를 추상화하고 불필요한 정보를 제거하여 답변 품질을 향상시킴을 증명
- 태스크 적응형 요약을 통해 불필요한 컨텍스트를 제거하면 LLM 비용 효율도 향상됨
5. Conclusion
- 유사성 기반의 기존 RAG 한계를 극복하기 위해 Multi-layered Thoughts(similarity-oriented thought, utility-oriented thought, compactness-oriented thought) 기반의 METRAG를 제안
- METRAG는 검색 문서의 유사성 뿐만 아니라 유용성을 함께 고려하고, 검색된 문서 정보를 Task Align 요약하여 RAG 성능을 향상시키고 계산 비용을 절감함
- 오픈 도메인 QA를 포함한 다양한 데이터셋에METRAG의 성능을 입증
# 참고한 자료